VLN课程学习笔记
详解DeepSeek-R1核心强化学习算法:GRPO https://zhuanlan.zhihu.com/p/21046265072
VLN课程学习笔记
第四章 学习范式:IL&RL
部分可观测马尔可夫决策过程(POMDP)
Policy Learning
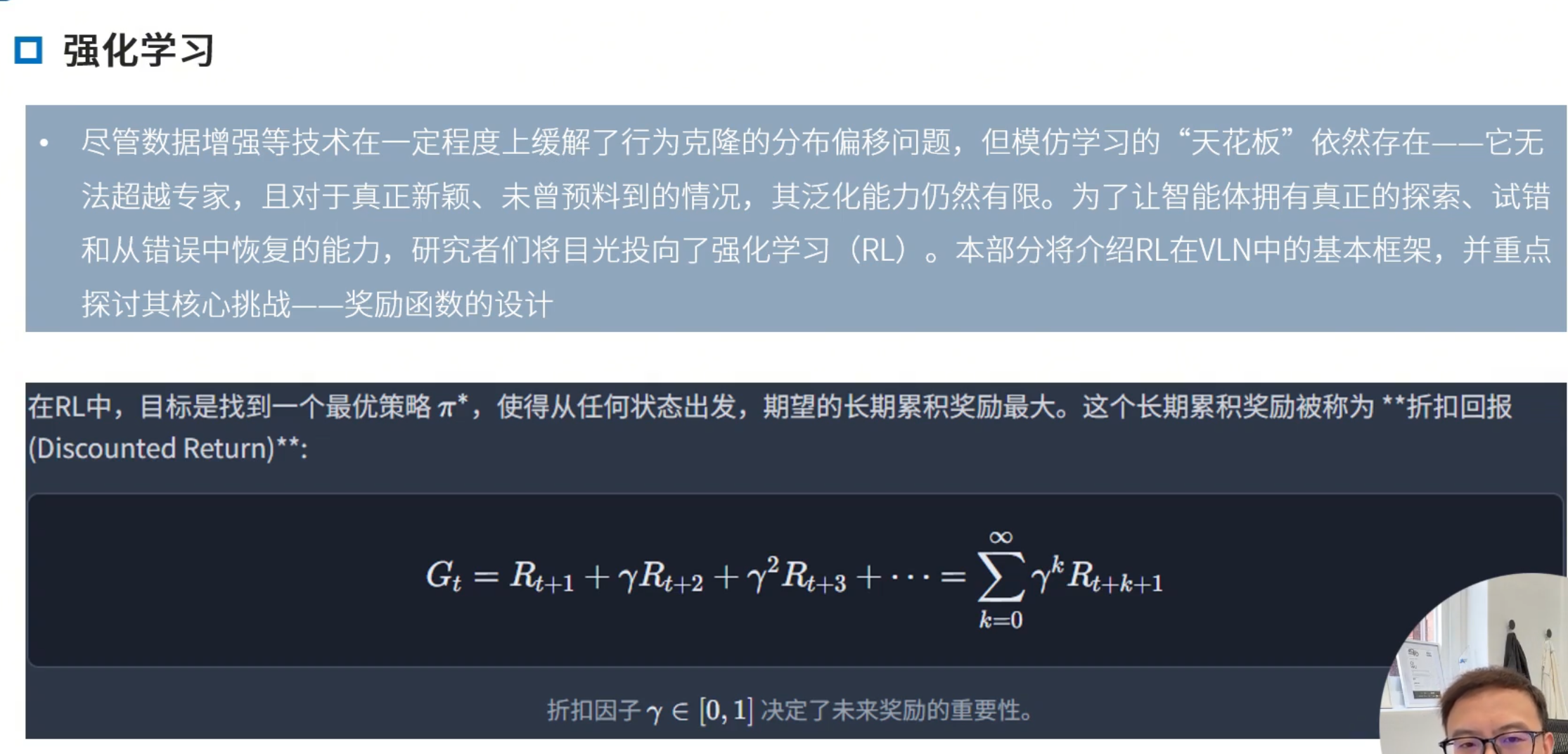
VLN的数学框架:本质上为一个在不确定性下的序列决策问题,用部分可观测马尔可夫决策过程决定(POMDP)


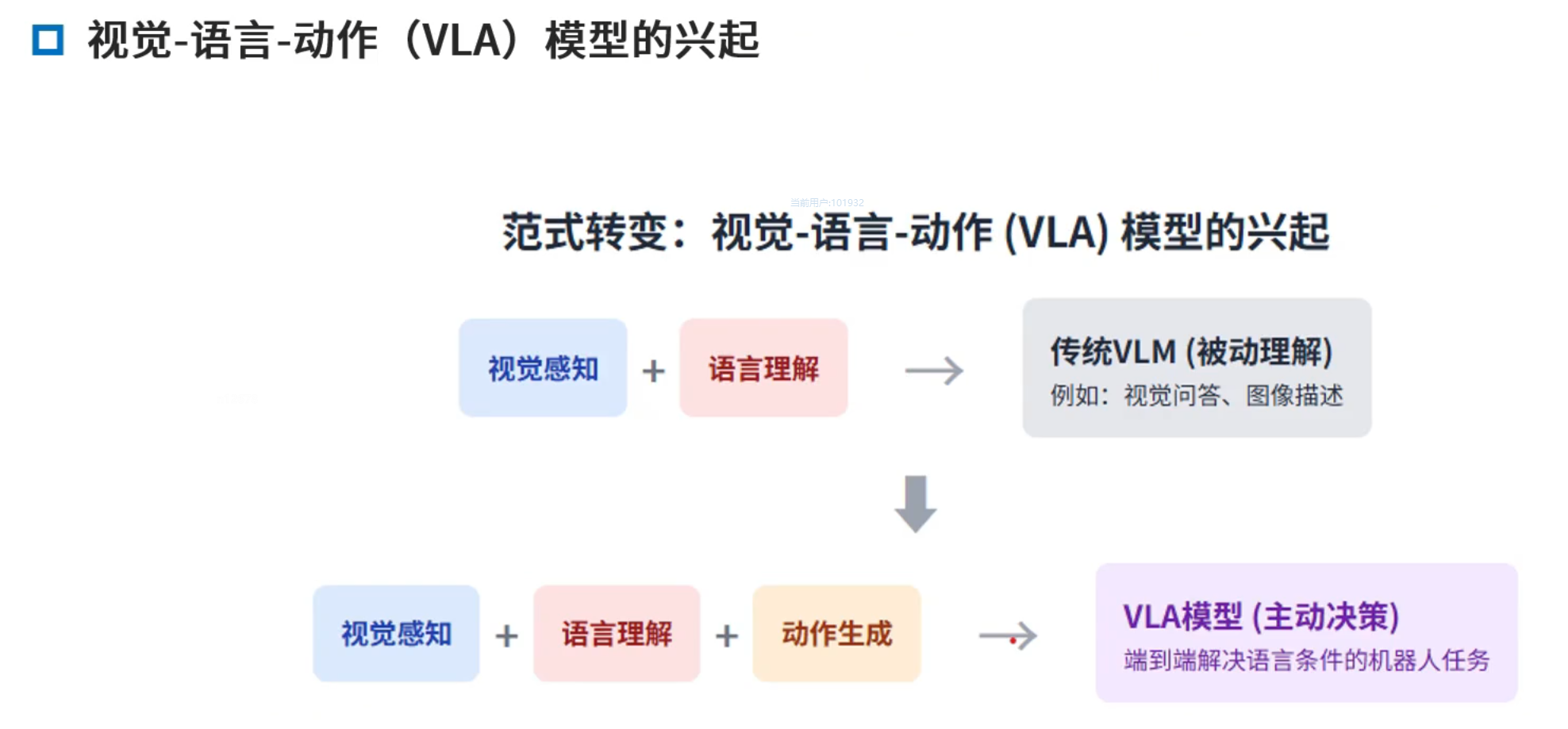
VLA

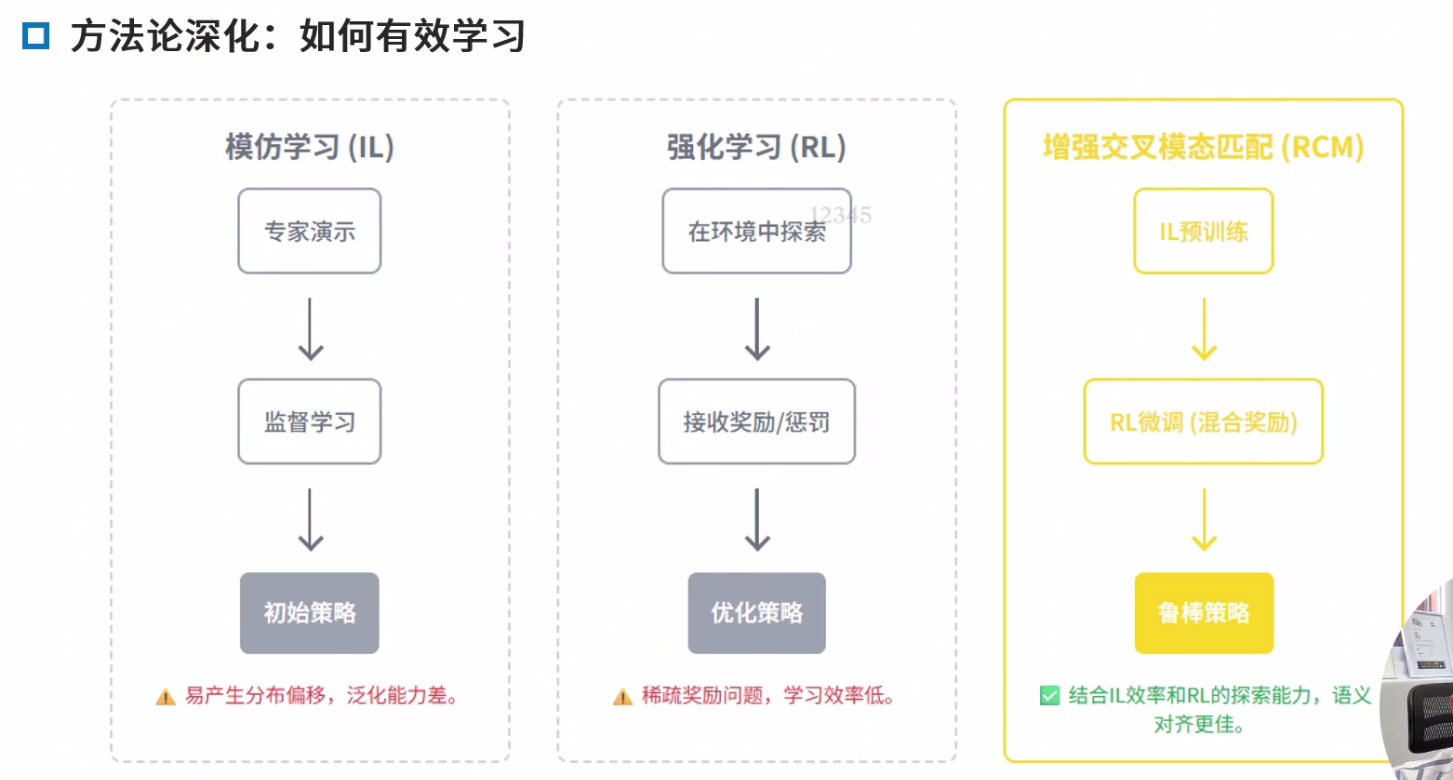
IL vs RL
模仿学习 将策略问题转换为分类器/回归问题


VLN比较复杂,所以也很难学习到有效的策略

更高效的方法:模仿学习预训练,快速掌握基本知识 + 强化学习优化,更有鲁棒性
模仿学习

典型:seq2seq模型



数据增强:Speaker-Follower模型
Speaker-Follower Models for Vision-and-Language Navigation

可以进行一定的增强,但是没办法超越“专家”
所以
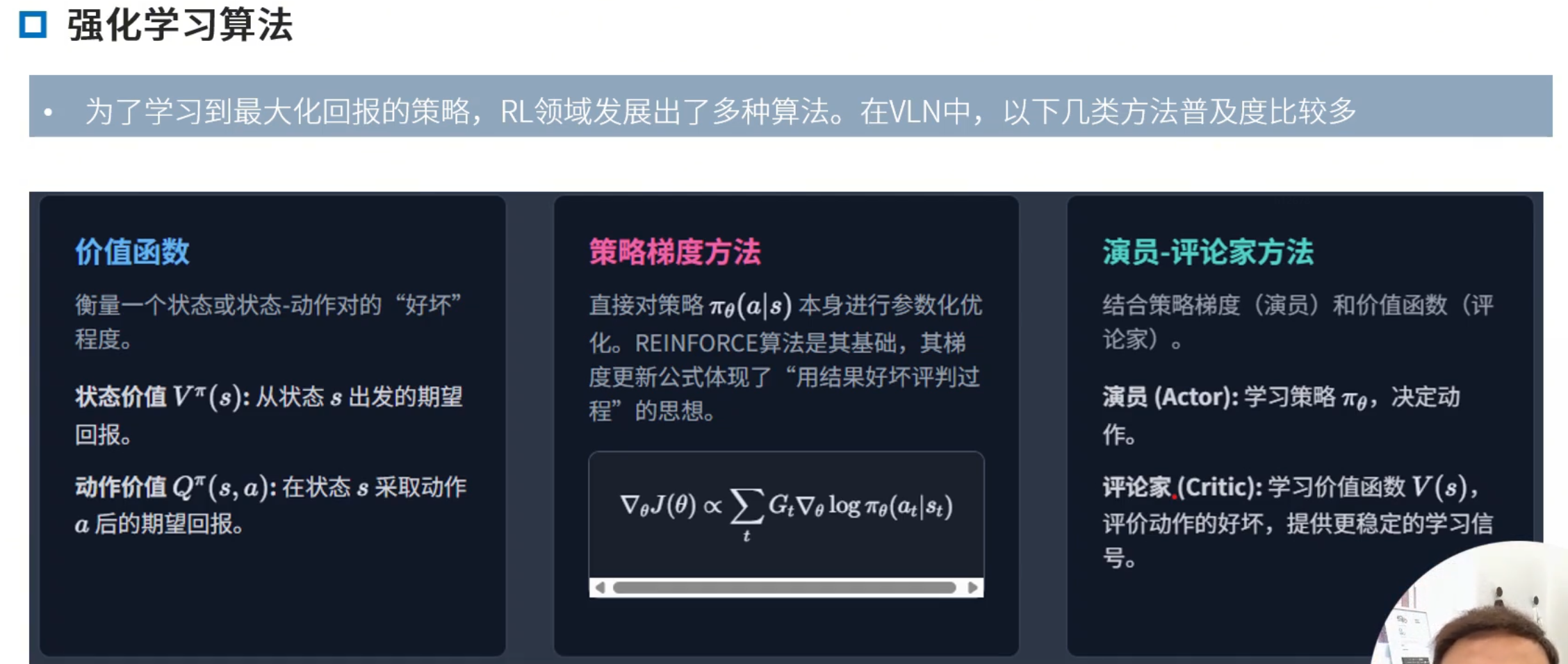
强化学习
Q-learning 价值函数
奖励函数是强化学习里面唯一的学习信号
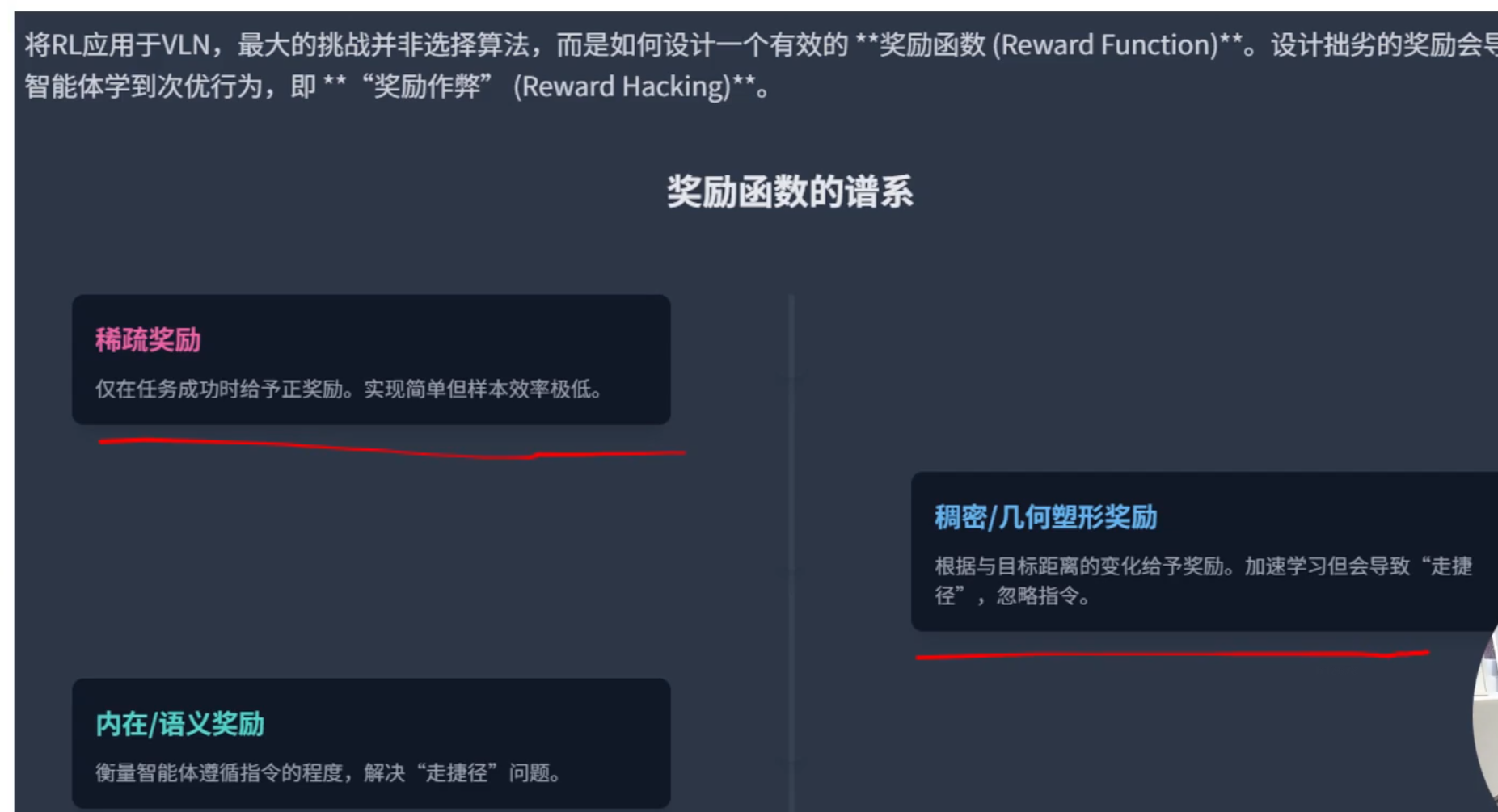
稀疏奖励:最直接,是否到达目标为正奖励,直接以目标为导向,但奖励信号 但是困难 且不一定能收敛
稠密/几何奖励:根据目标距离去给奖励,能加速学习,但是这样会忽略指令,会走捷径,如穿过某个东西后到达某地
内在/语义奖励:解决几何奖励的缺陷,是否遵循指令
典型:RCM模型,增强交叉模态匹配

内在奖励:语义(路径保真度,语义一致性挂钩)
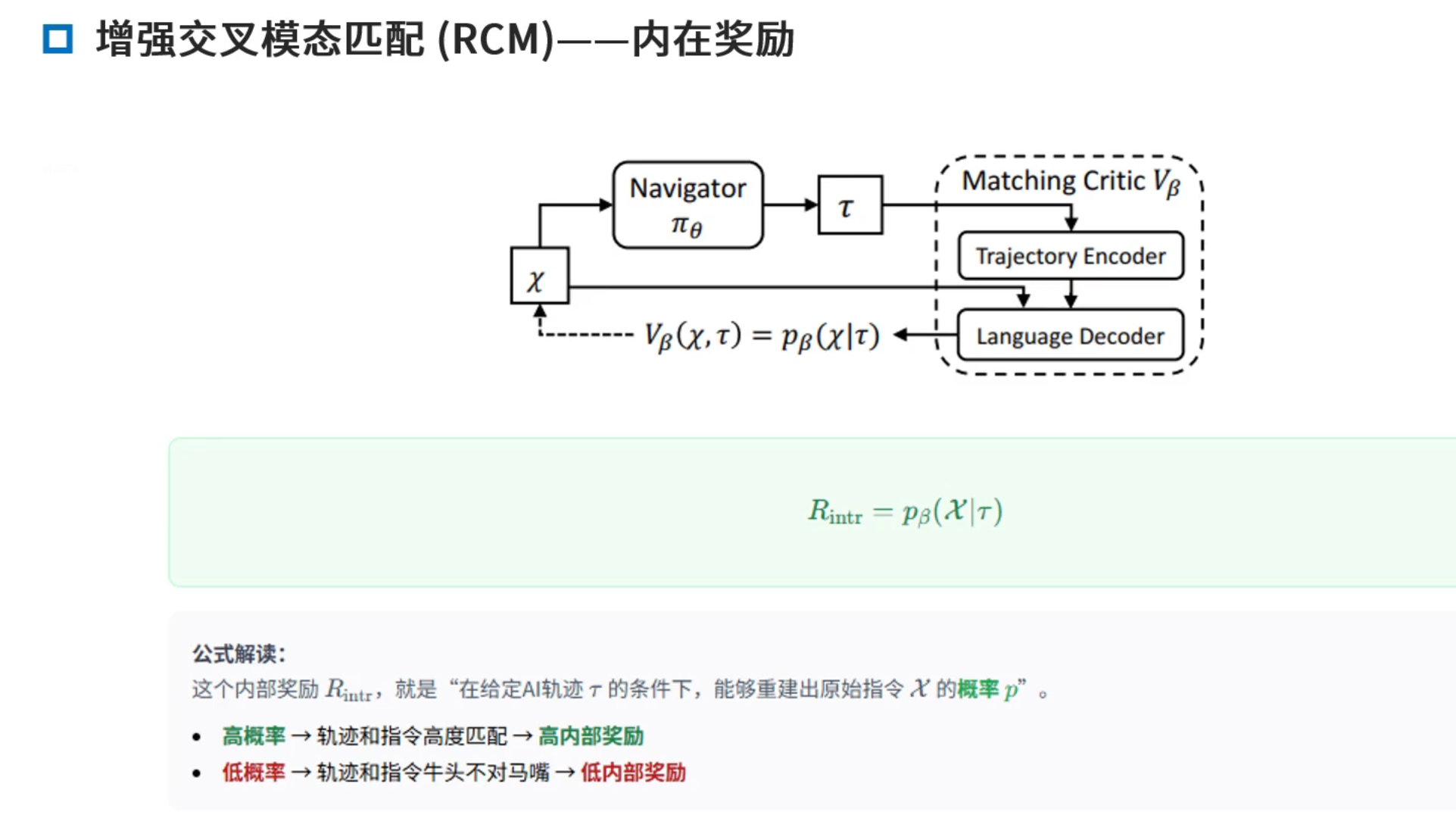 我的路径与文字是否匹配,不展开介绍
我的路径与文字是否匹配,不展开介绍
外在奖励:实时导航奖 + 成功抵达奖

终极策略:

优势函数
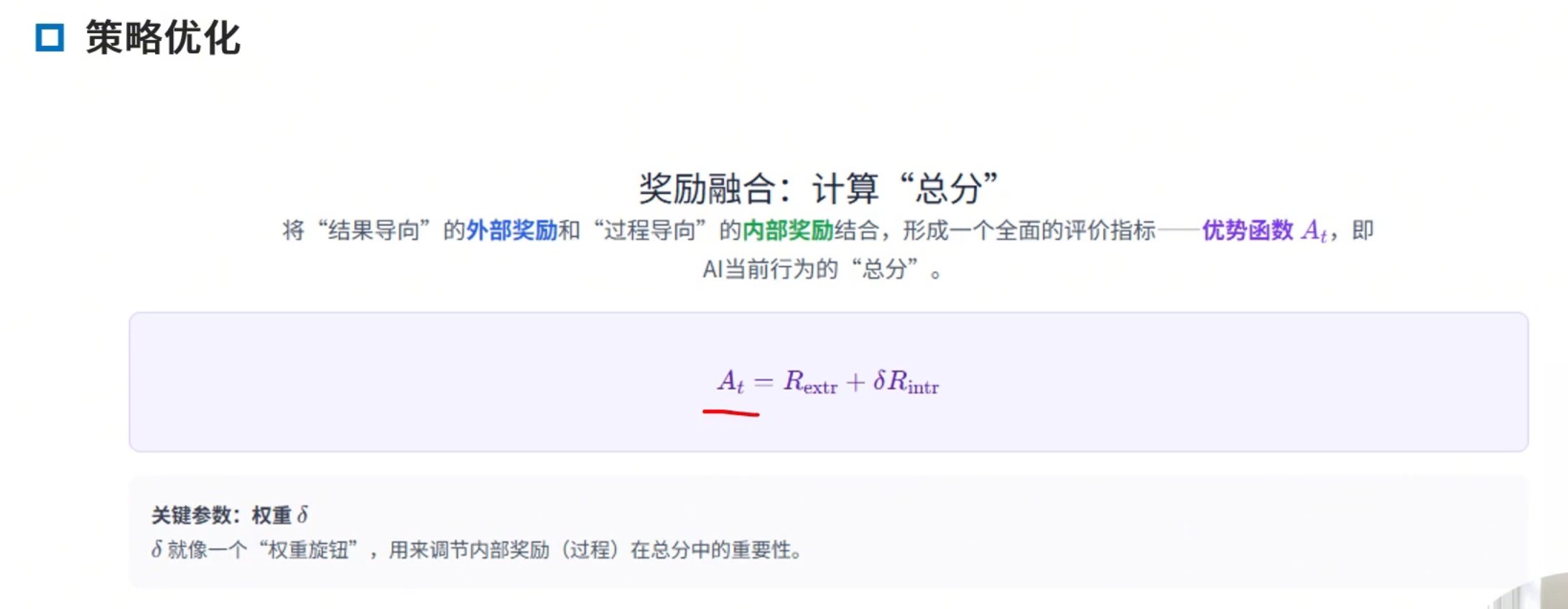
损失函数最小化-总分最大化 转化
梯度-优化方向


混合方法:IL + RL


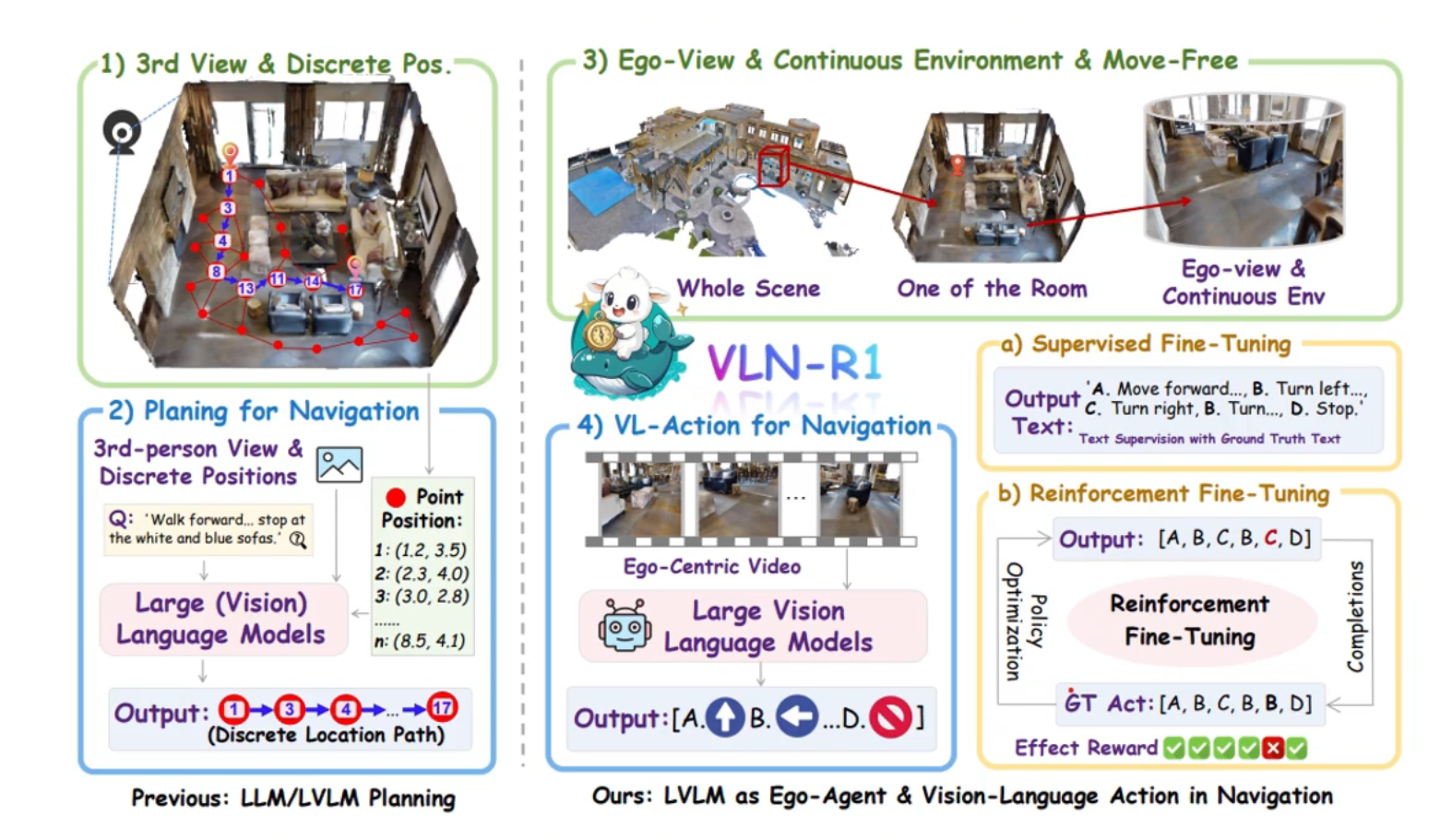
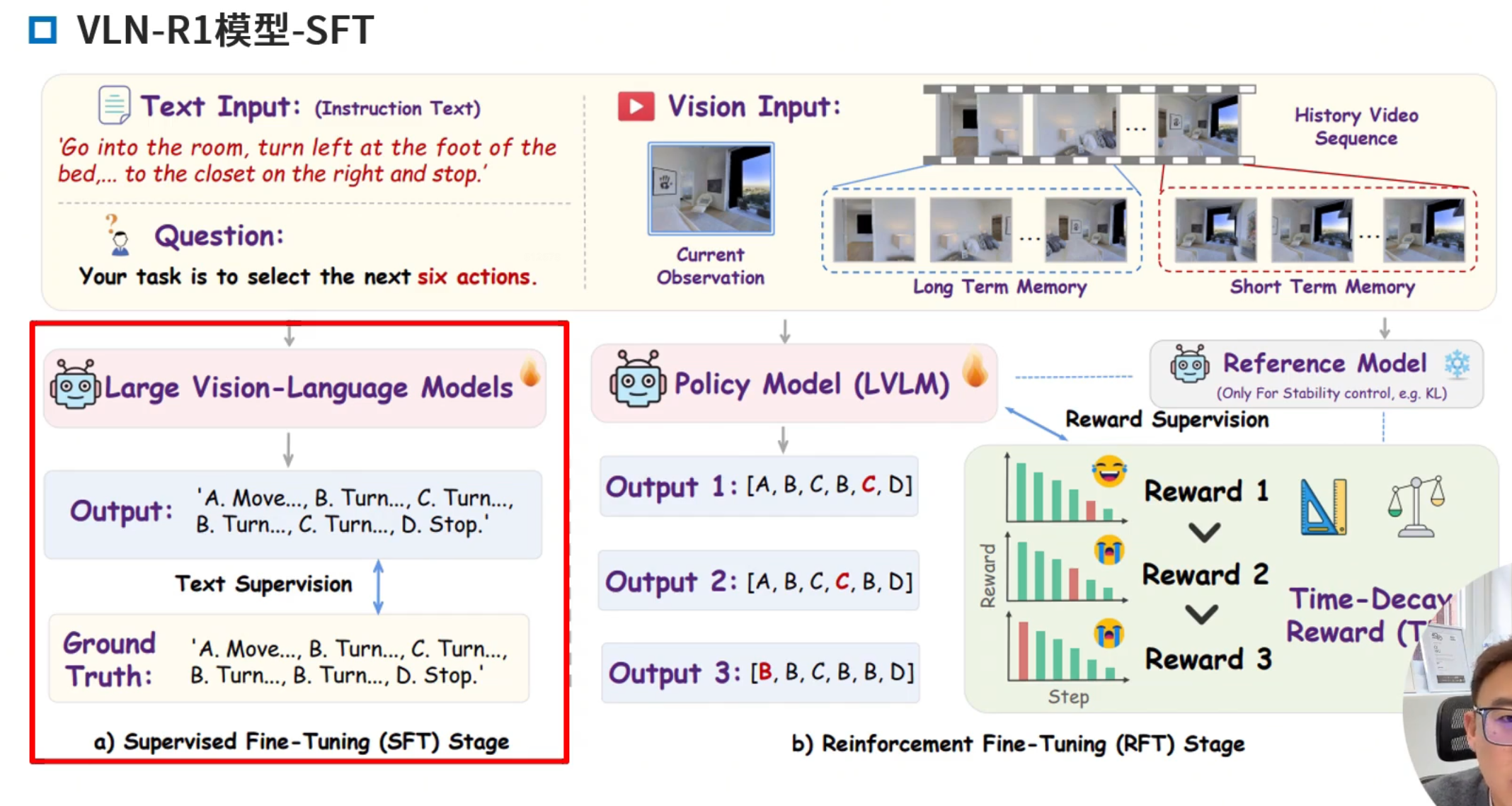
典型:VLN-R1
VLN-R1: Vision-Language Navigation via Reinforcement Fine-Tuning
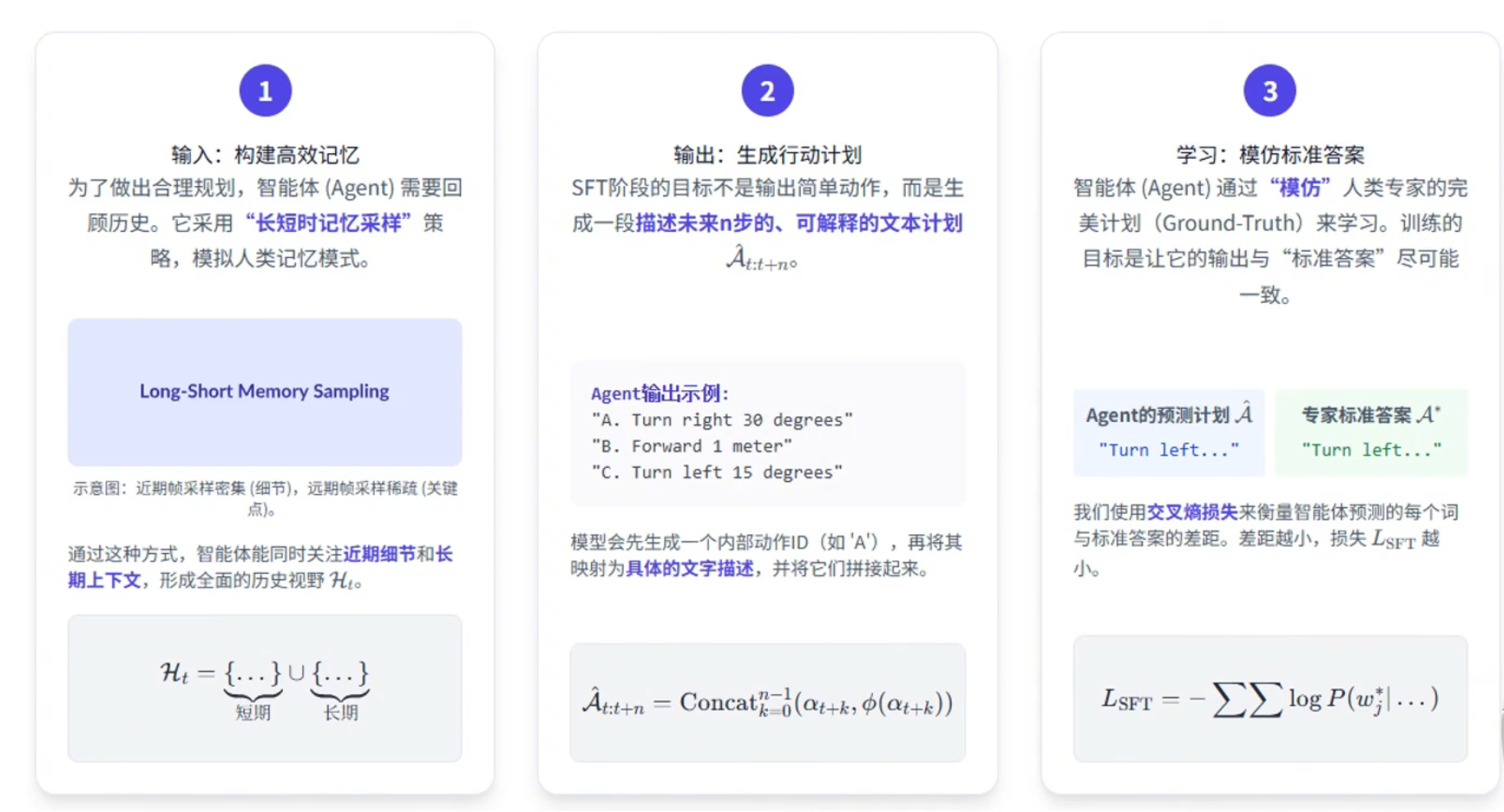



第五章 视觉语言预训练模型
Vision Language Pretraining
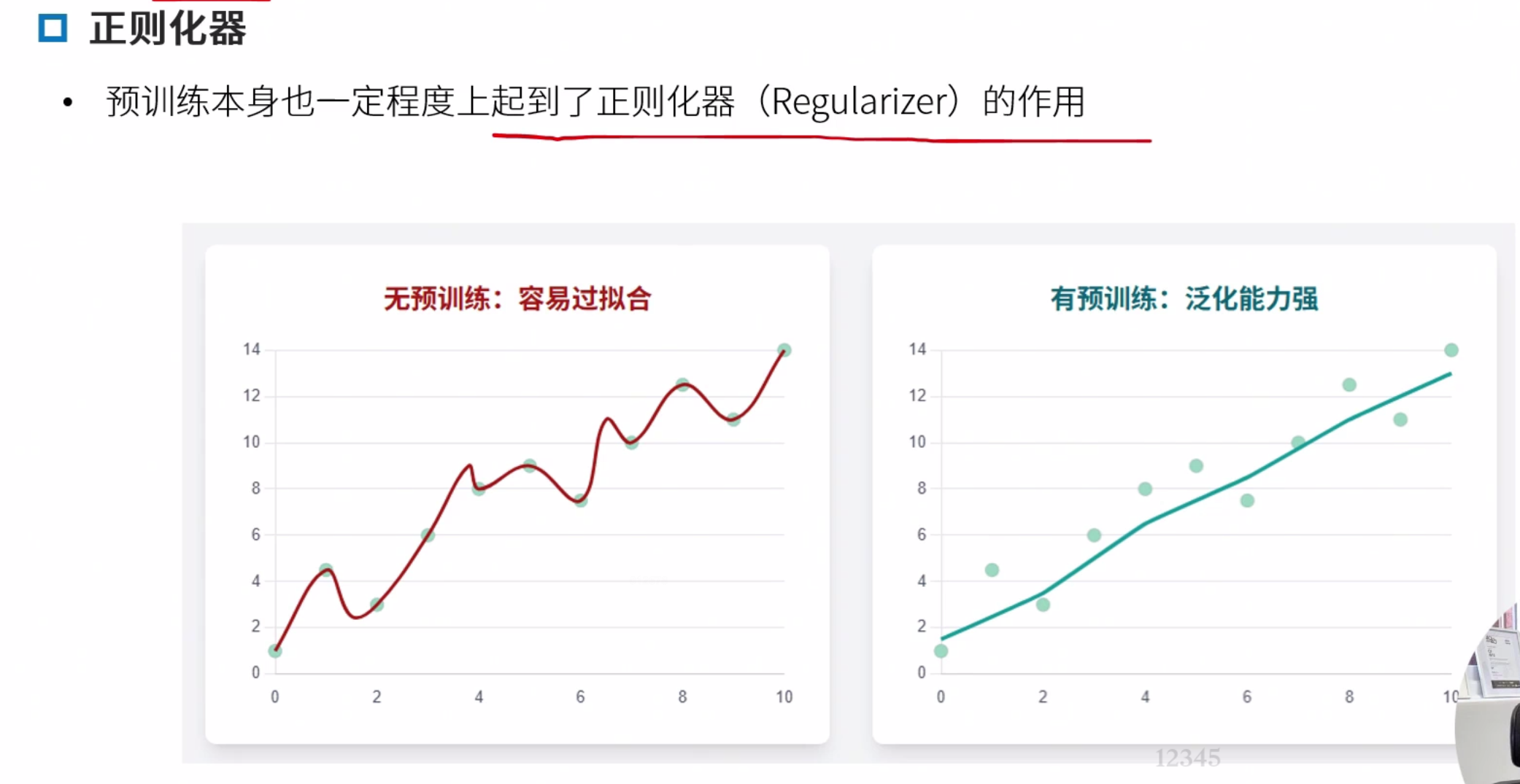
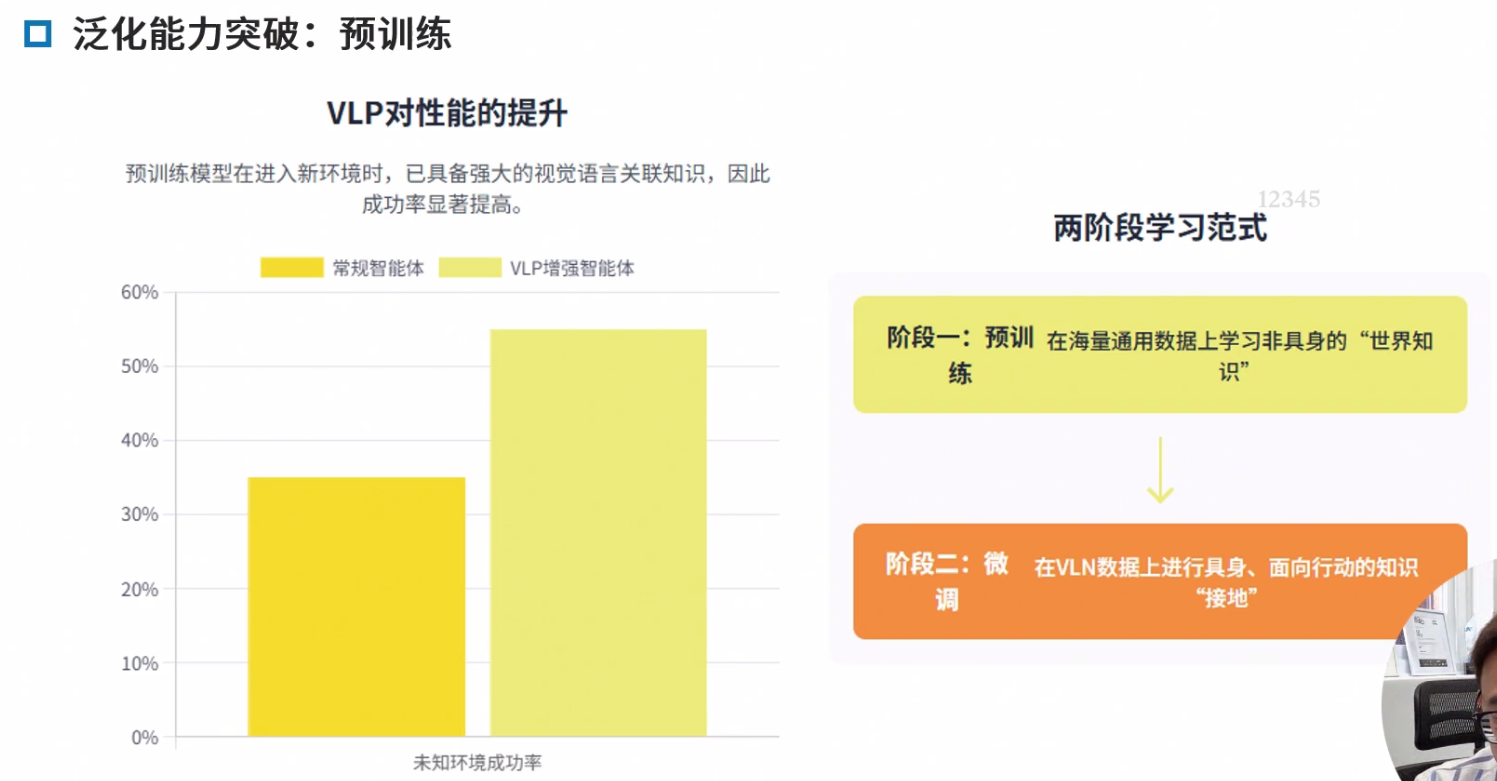
泛化鸿沟

预训练范式

自监督学习
从数据本身自动生成标签

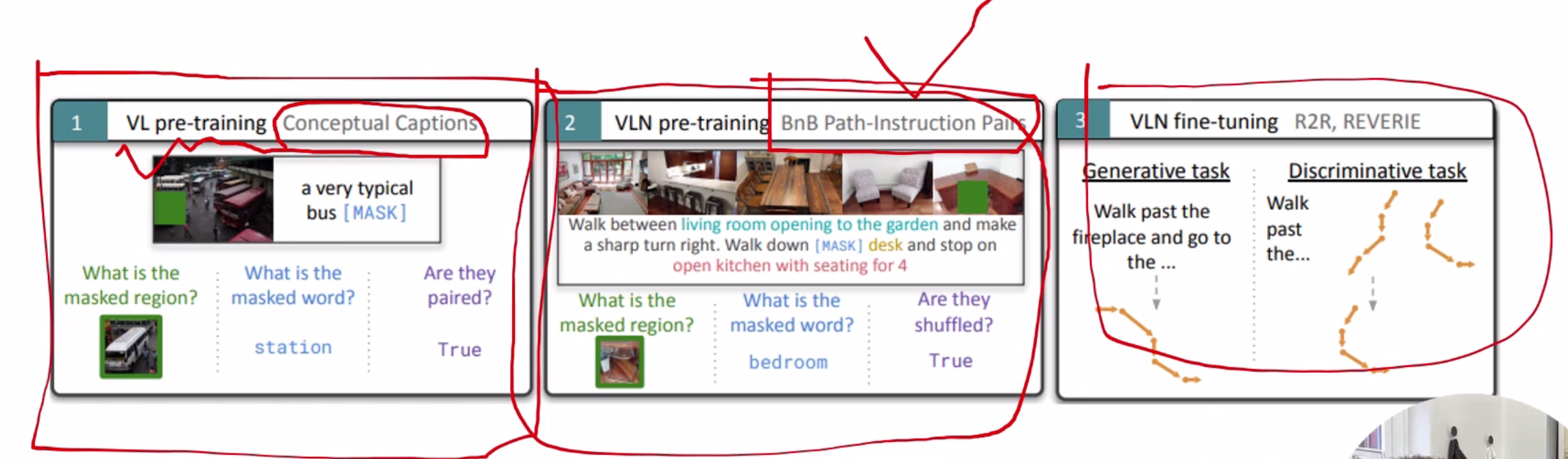
领域内与领域外预训练 领域内:类导航数据,优点任务相关性强,直接服务导航,缺点,早期数据集规模小,成本高 领域外:使用图文对(如网页图片)。优点 数据规模大 多样性高,缺点,与导航任务差异大,缺乏时序和动作信息。
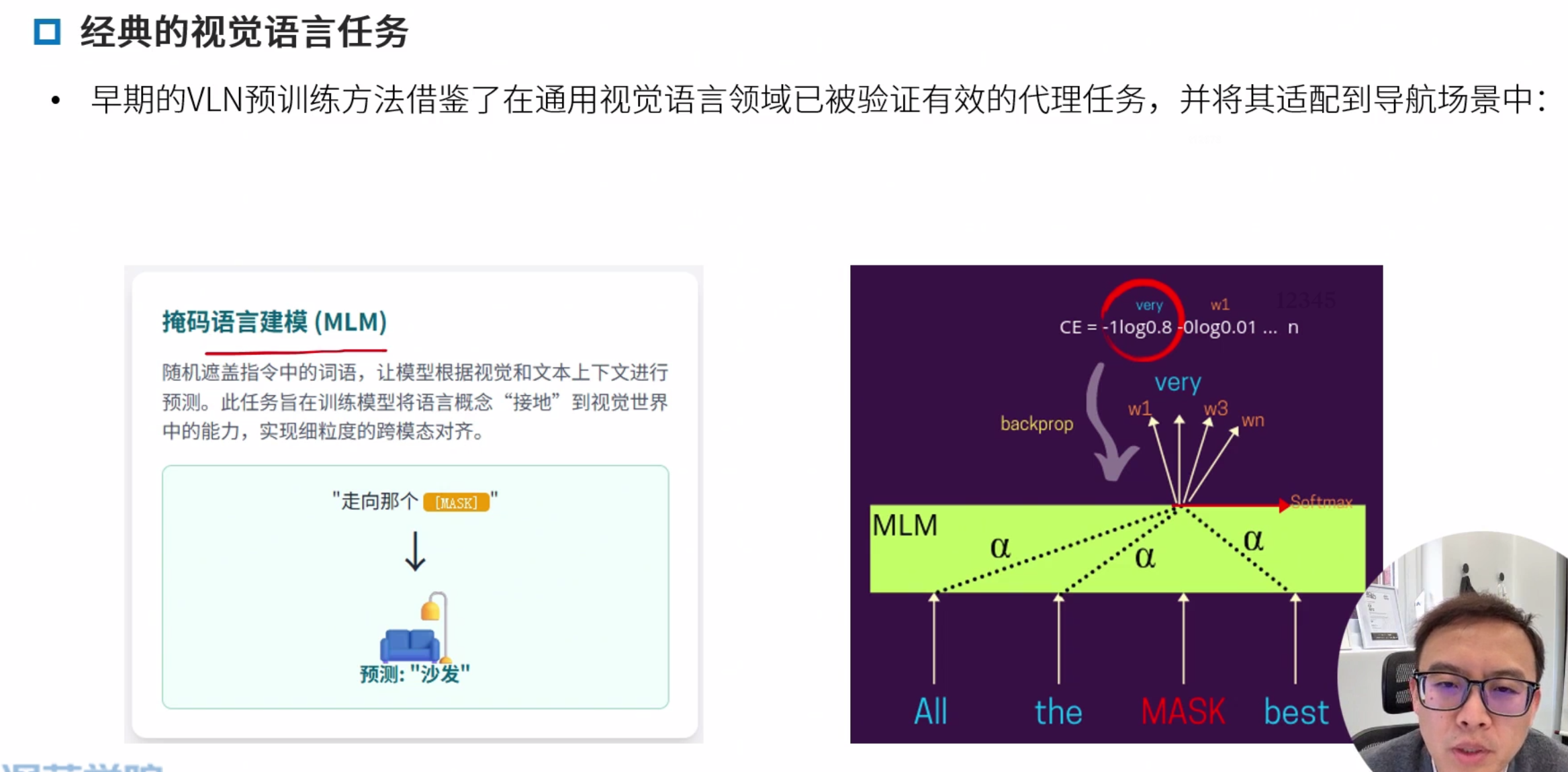
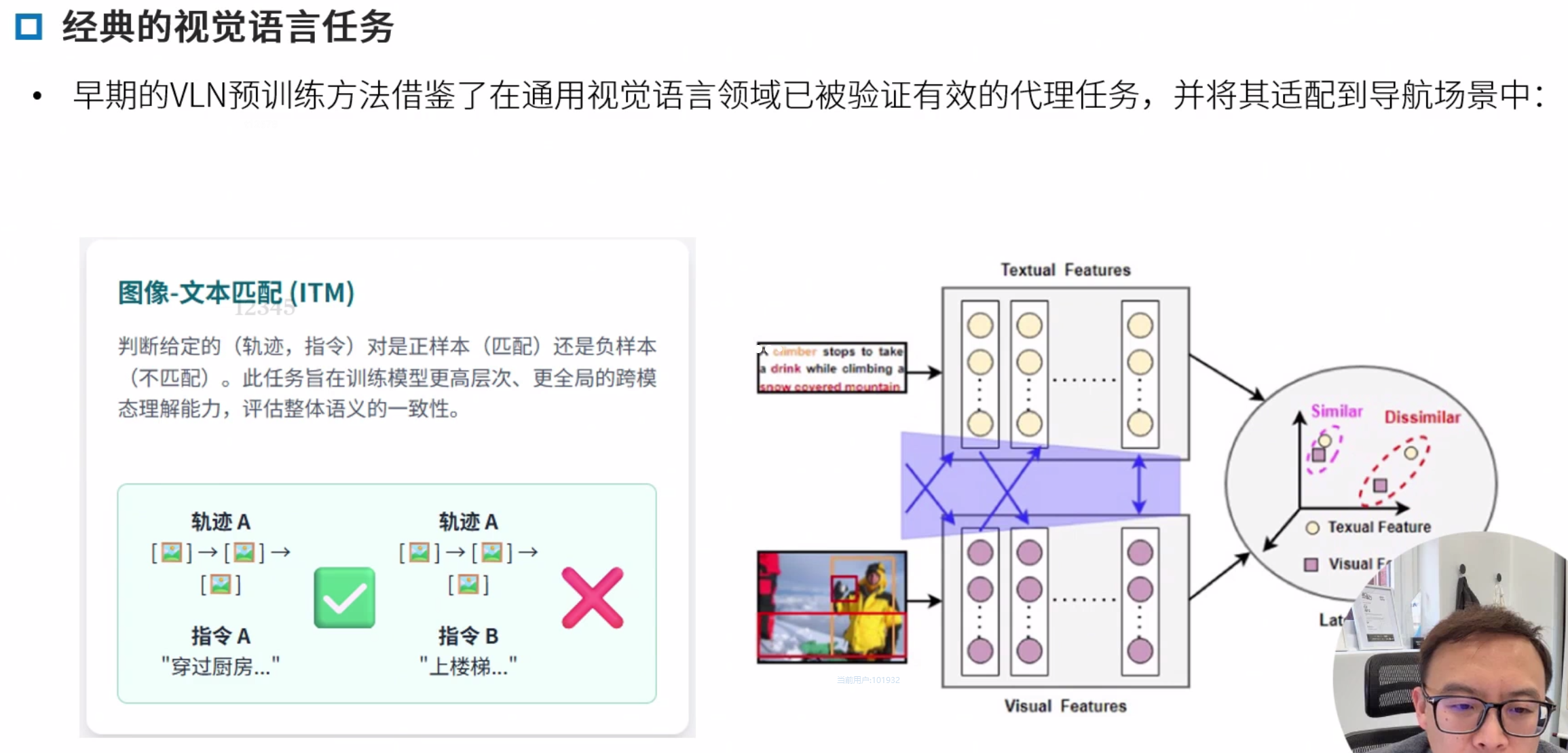
经典的视觉语言任务
Masked Language Model


预训练经典架构
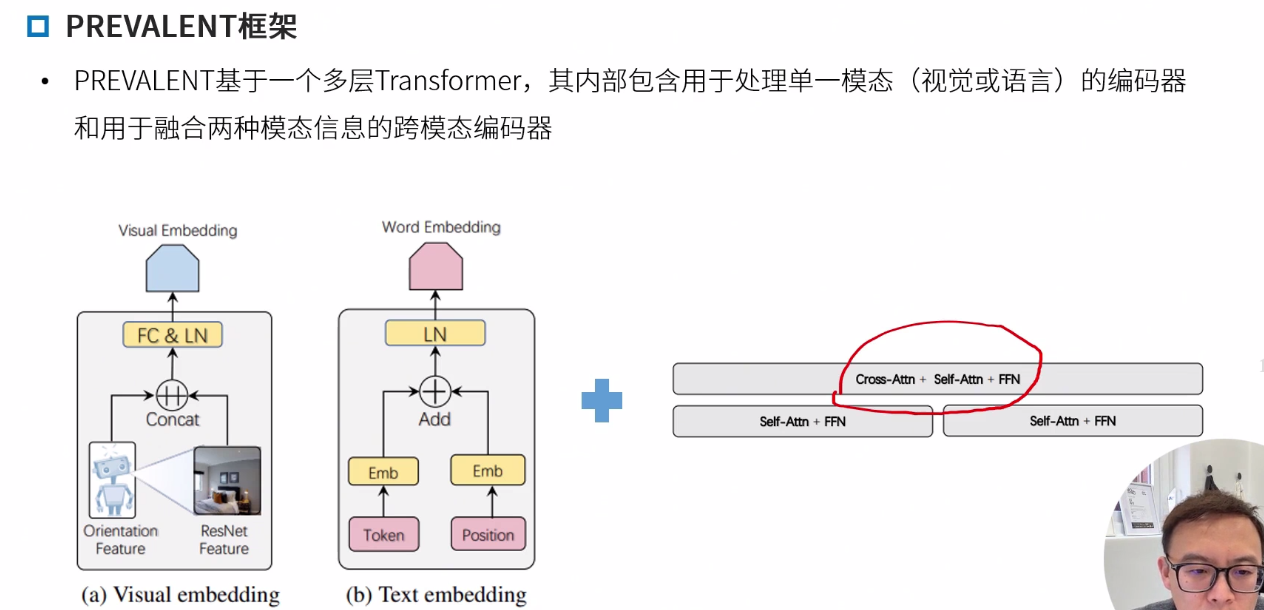
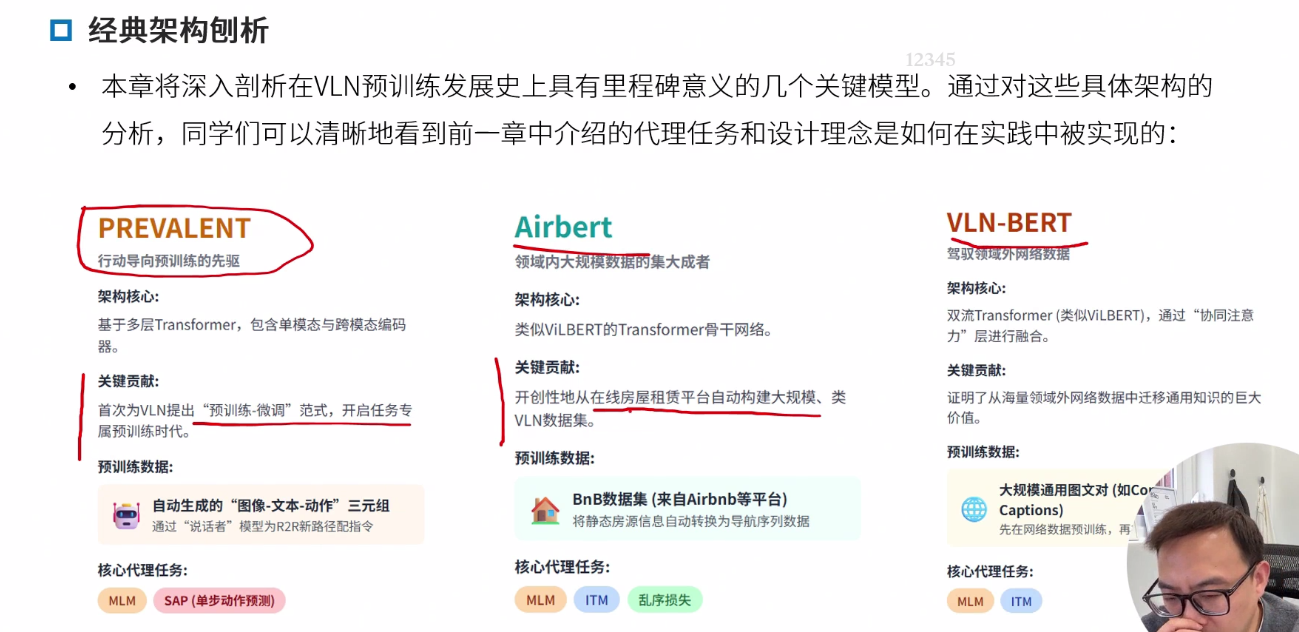
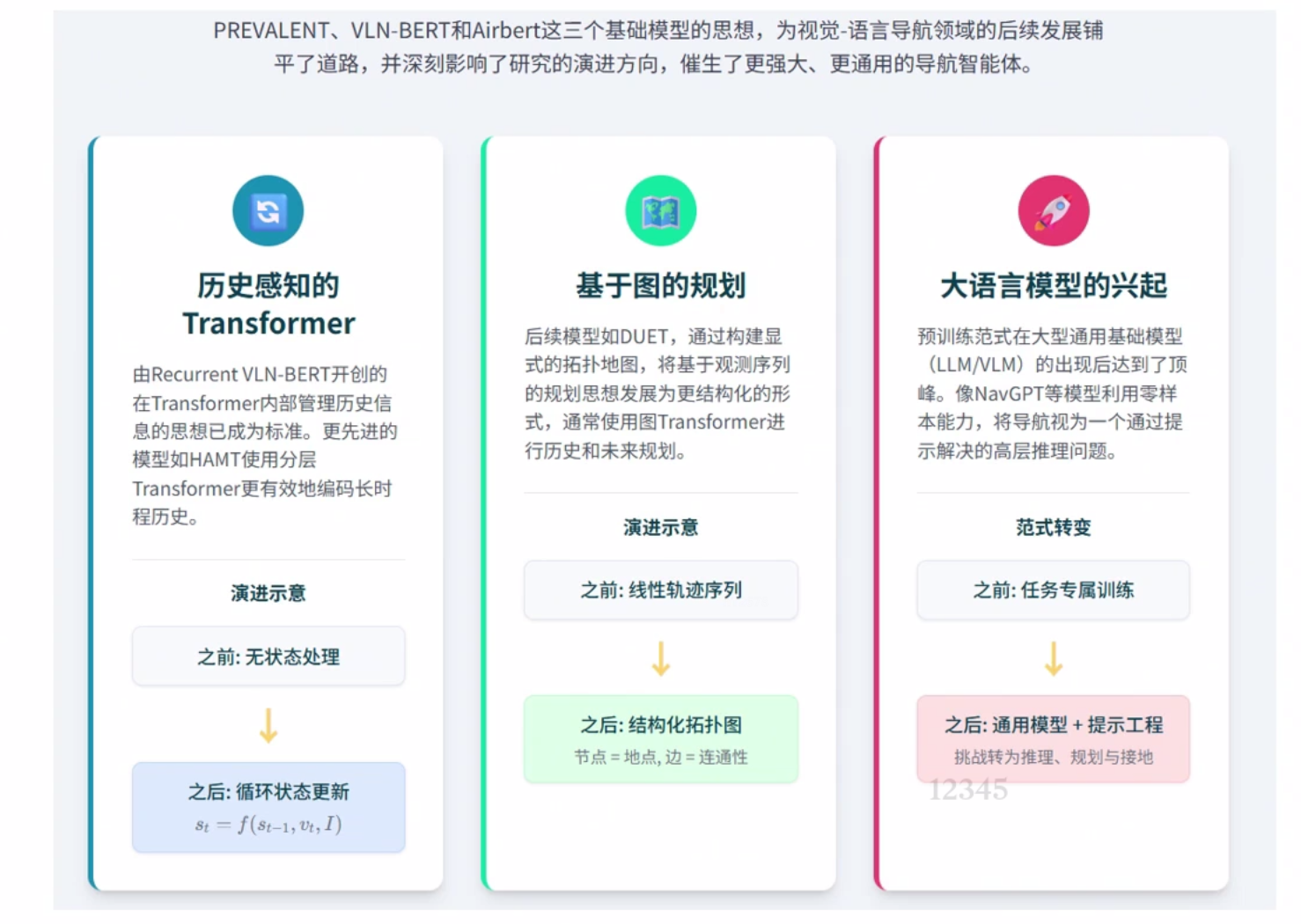
PREVALENT
最早提出预训练的 Towards Learning a Generic Agent for Vision-and-Language Navigation via Pre-training


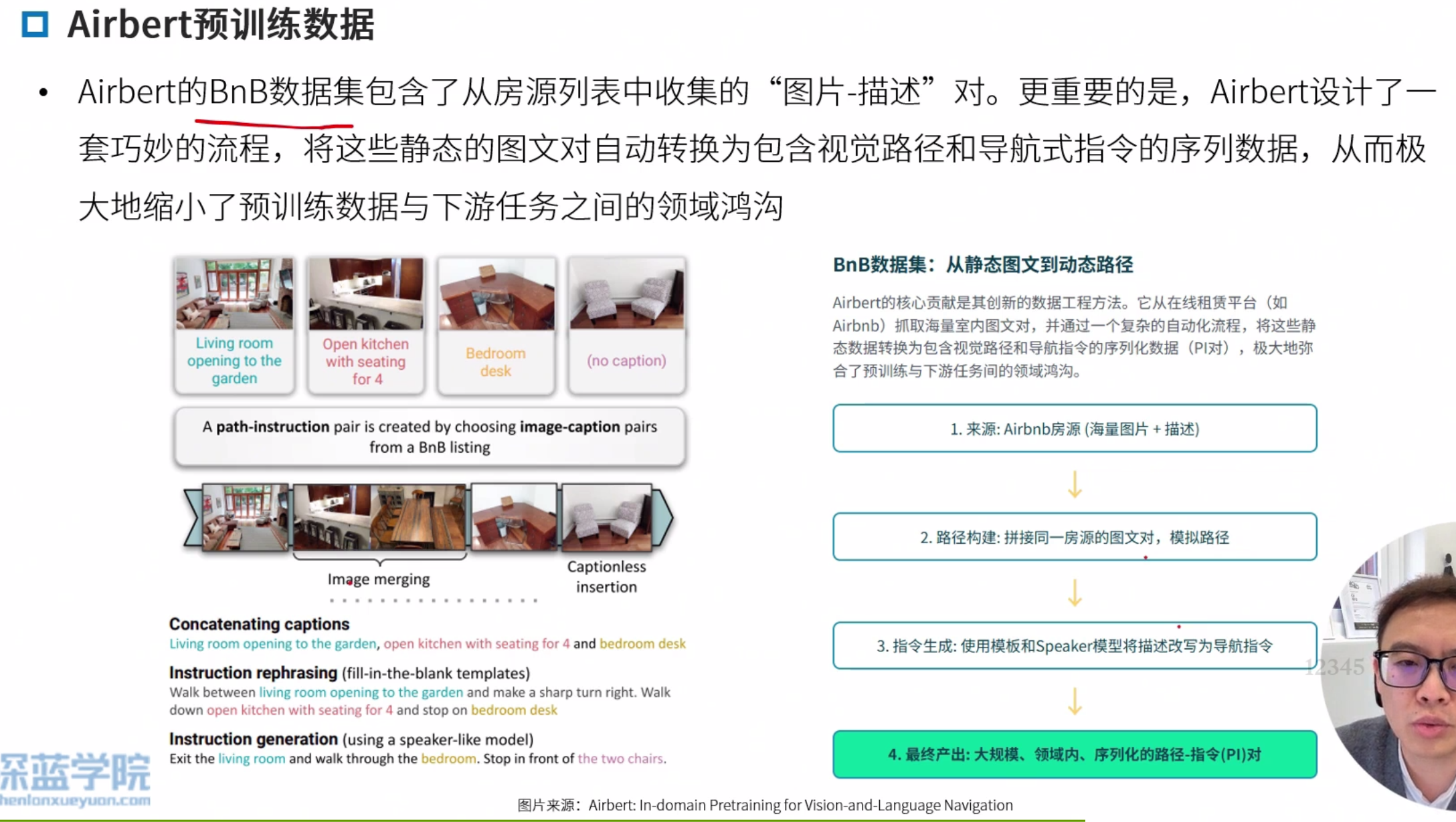
AirBert
Airbert: In-domain Pretraining for Vision-and-Language Navigation


Recurrent VLN-BERT
VLN-BERT: A Recurrent Vision-and-Language BERT for Navigation
可以用领域外的


预训练高级架构
BEVBERT
BEVBert: Multimodal Map Pre-training for Language-guided Navigation
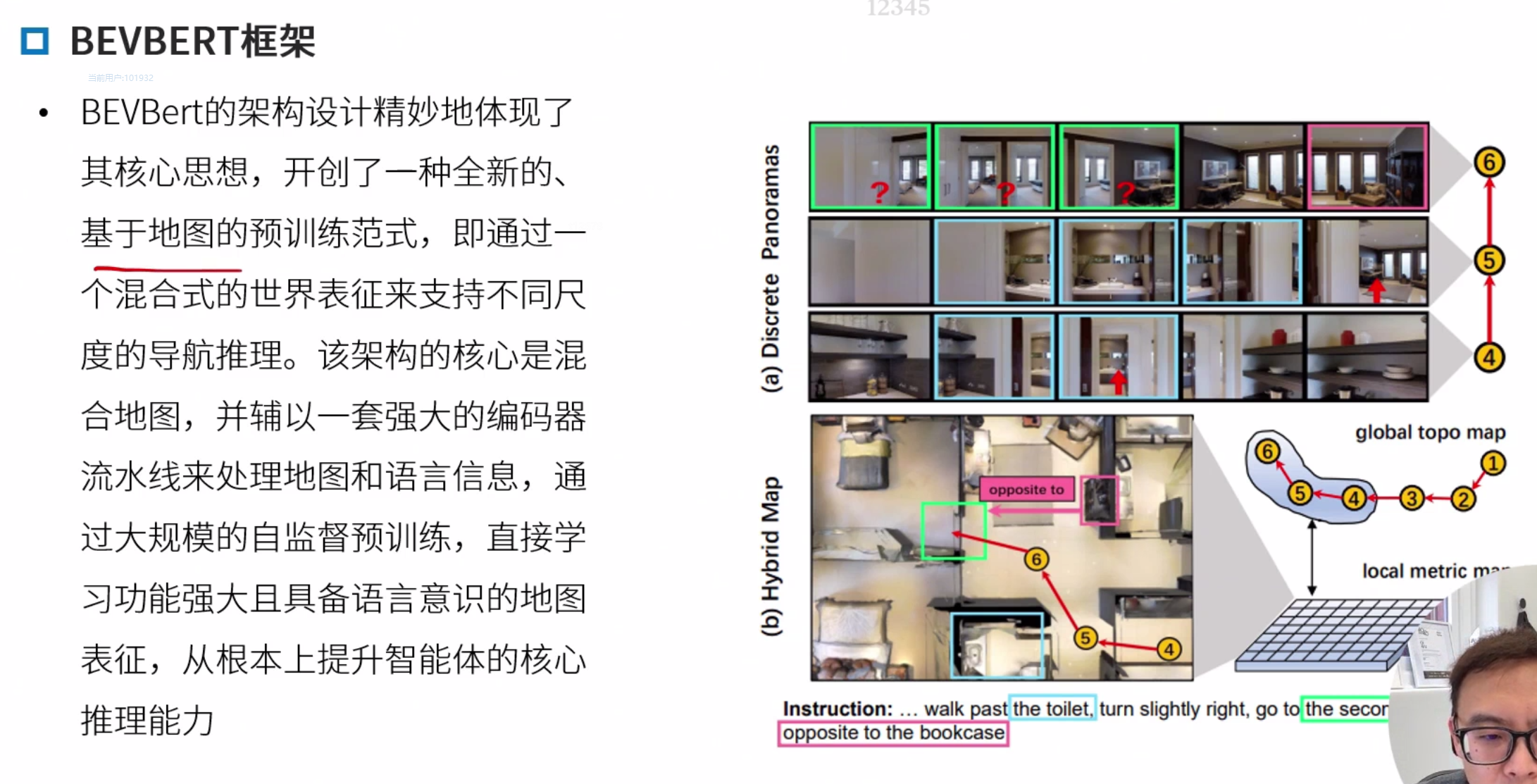
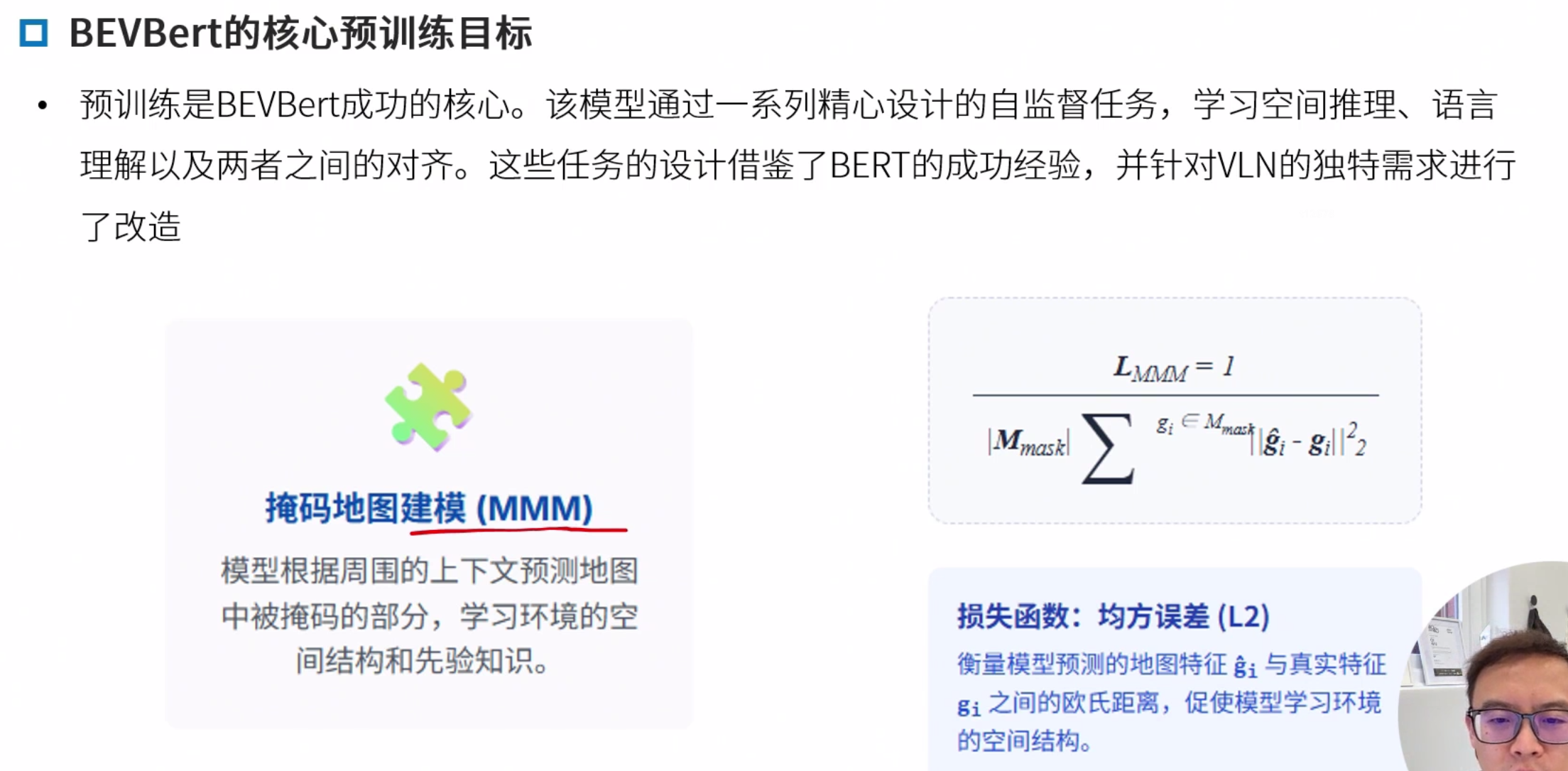

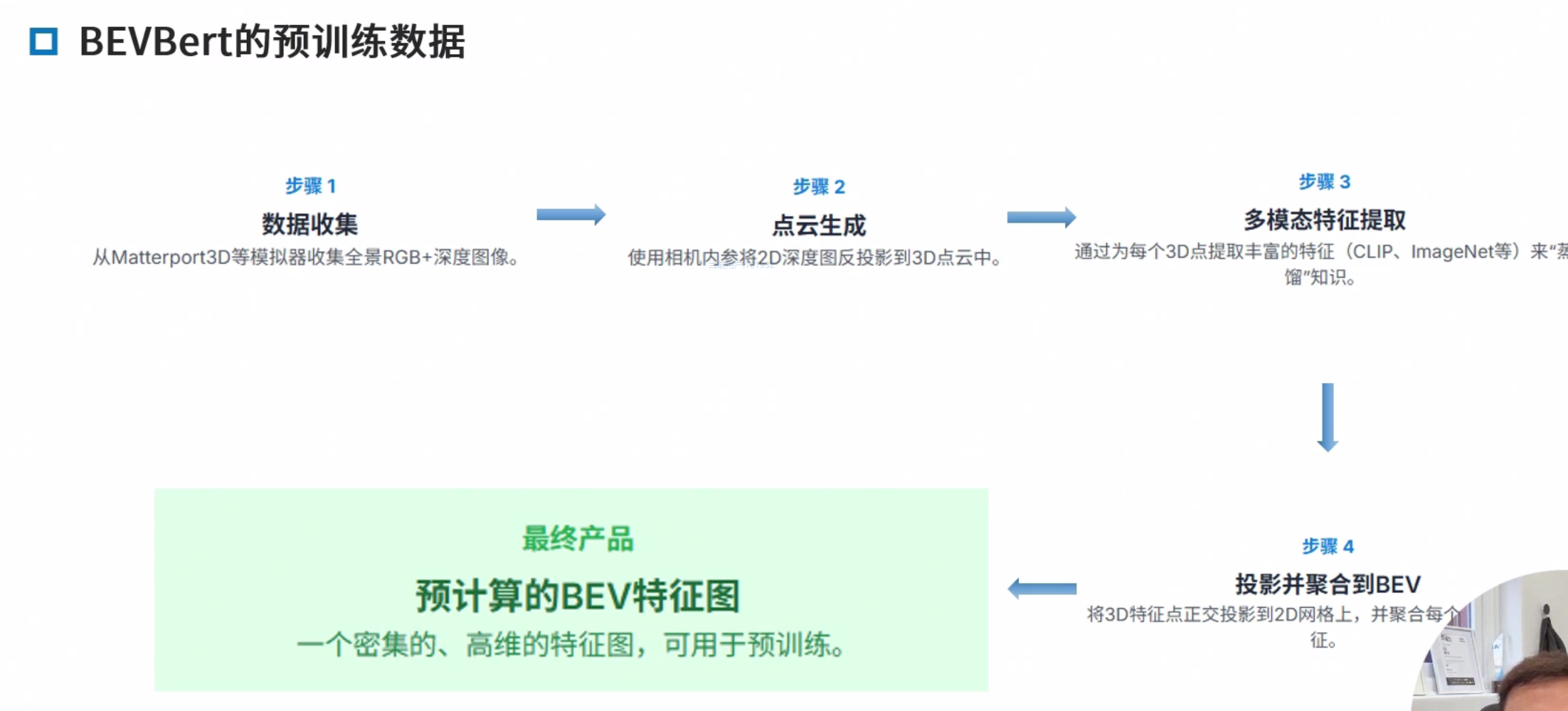
微调


这种范式是基于learning的
第六章 LLM与VLN的融合
传统VLN性能瓶颈
预训练的模型也可能对常识无法理解

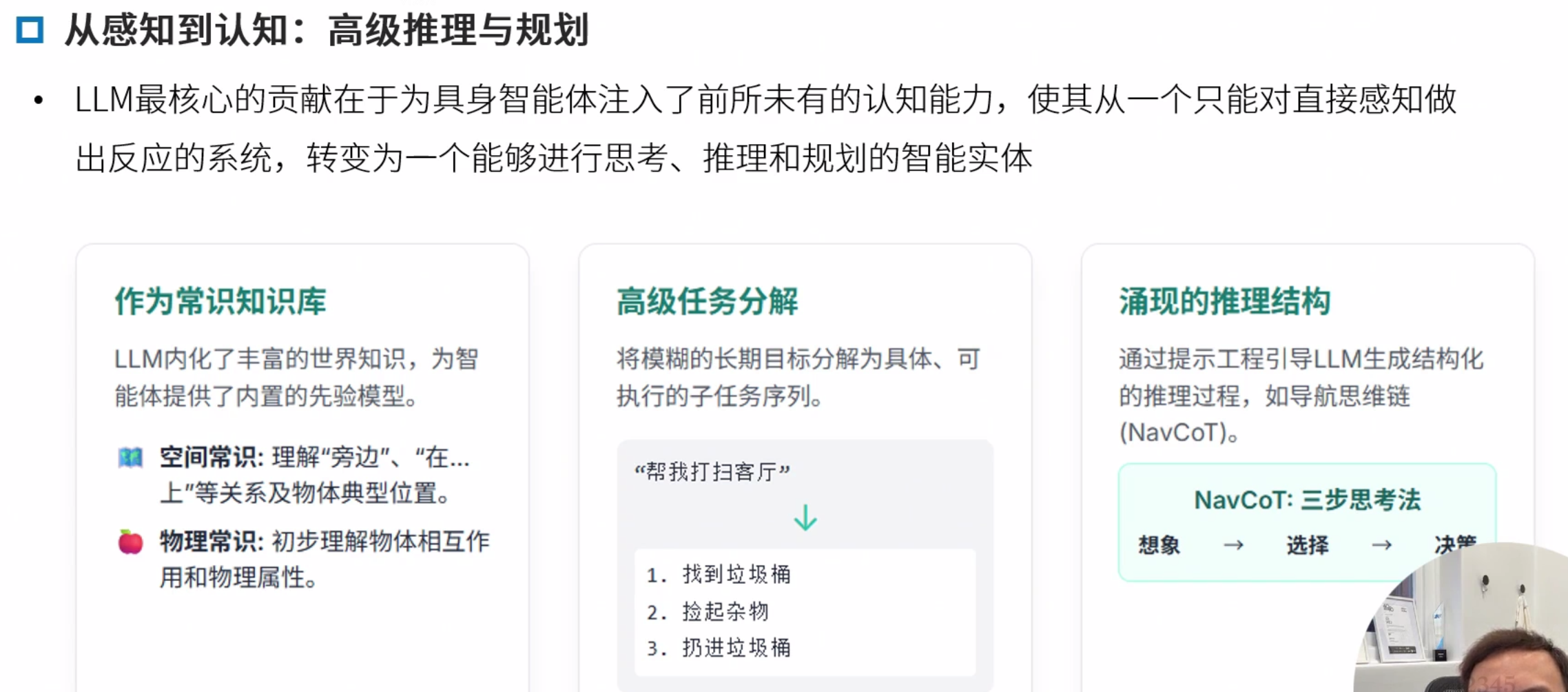
LLM的优势 强大的知识库
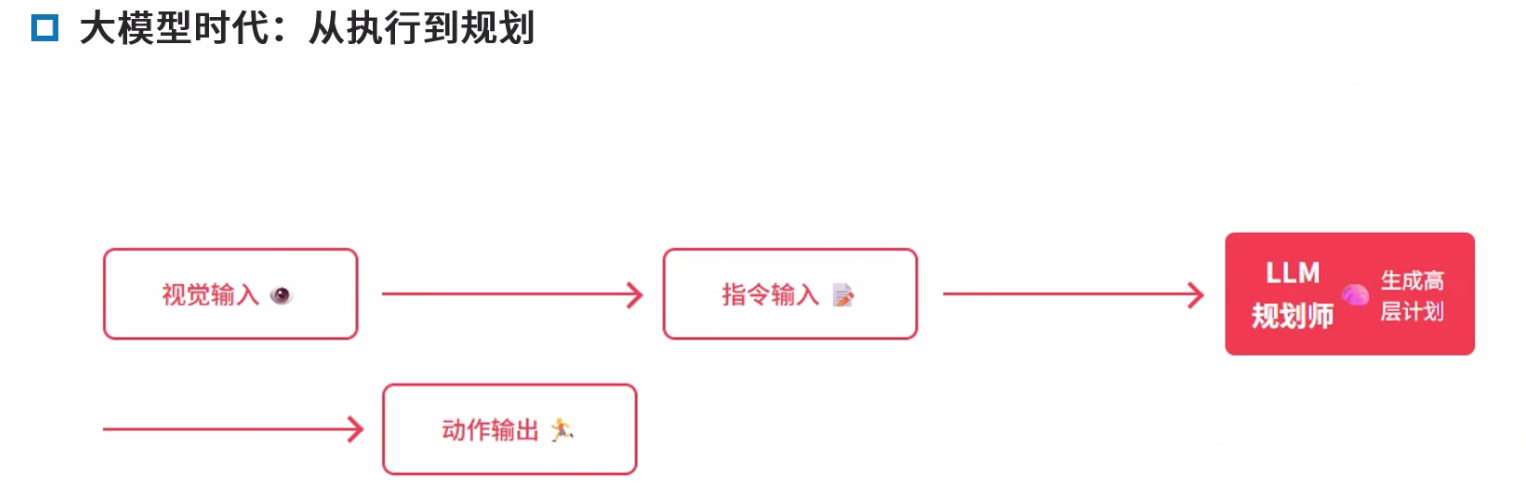
 从预测到推理的转变
从预测到推理的转变

IL&RL vs LLM

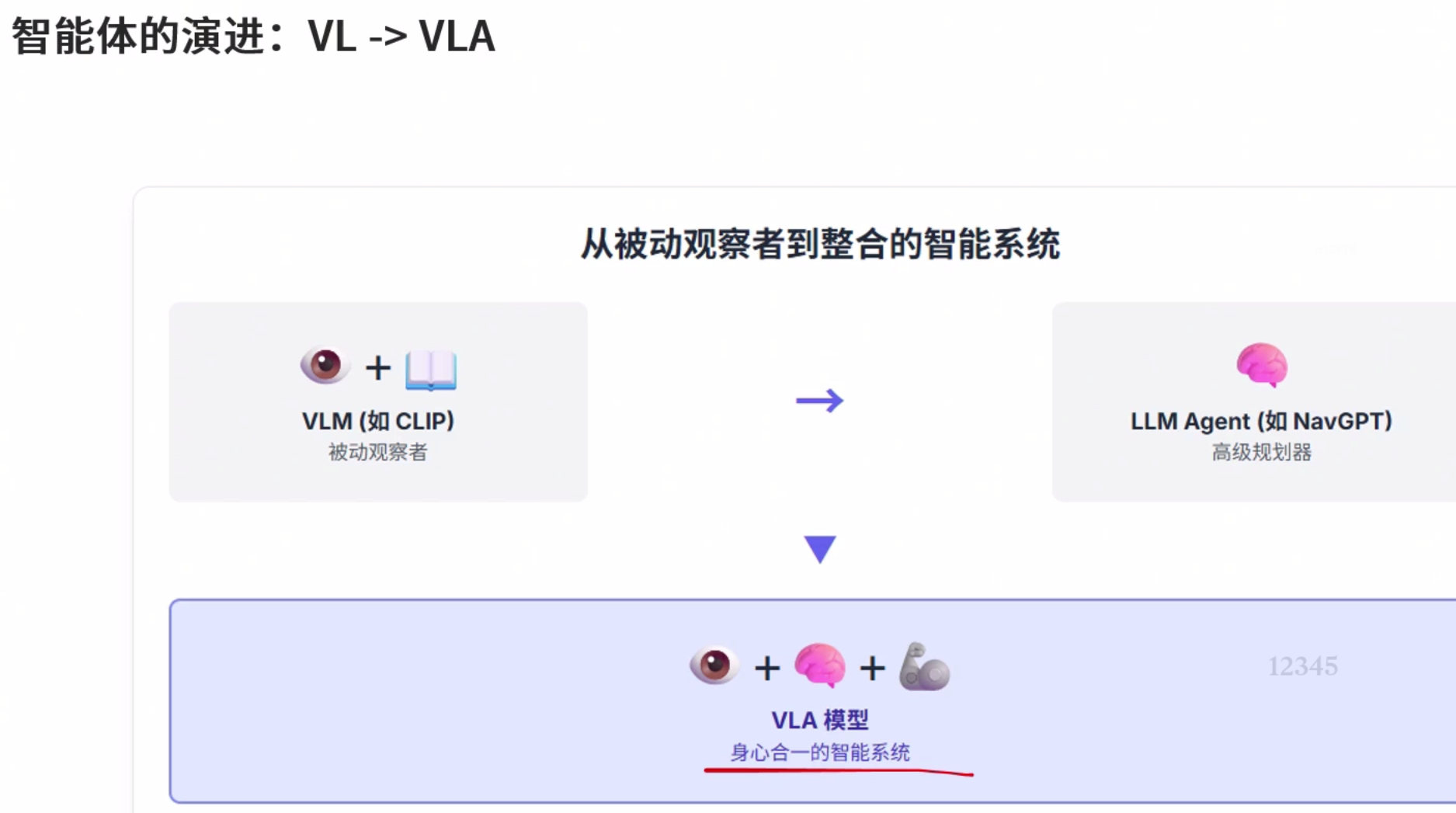
CLIP
LLM的优势
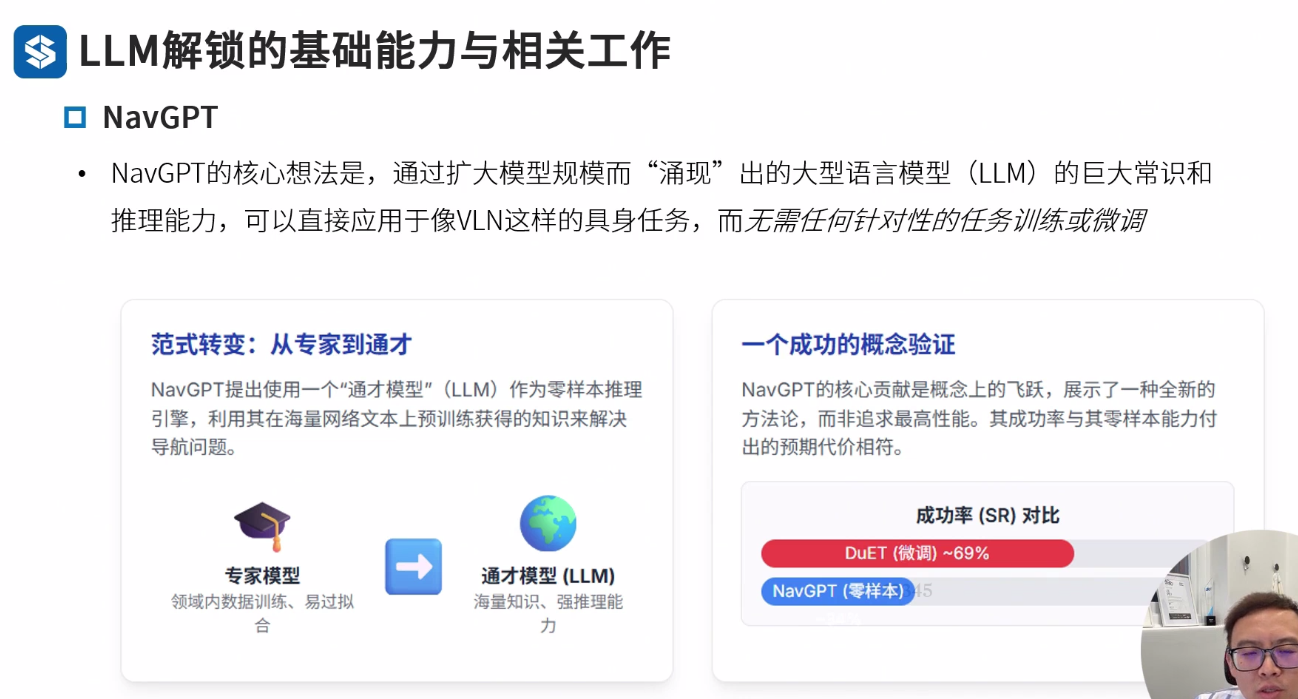
NavGPT 高级规划器
NavCoT NavCoT: Boosting LLM-Based Vision-and-Language Navigation via Learning Disentangled Reasoning
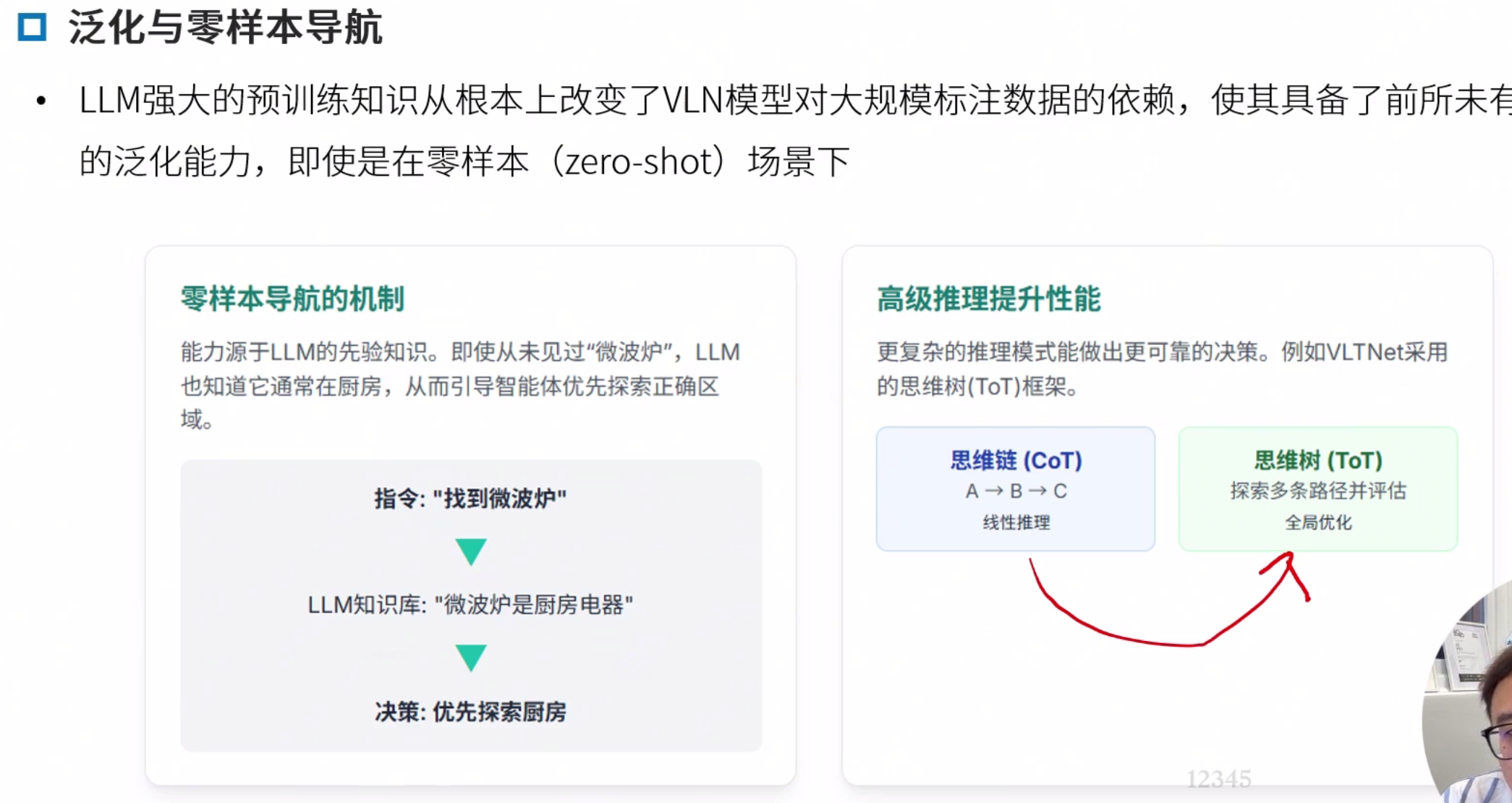
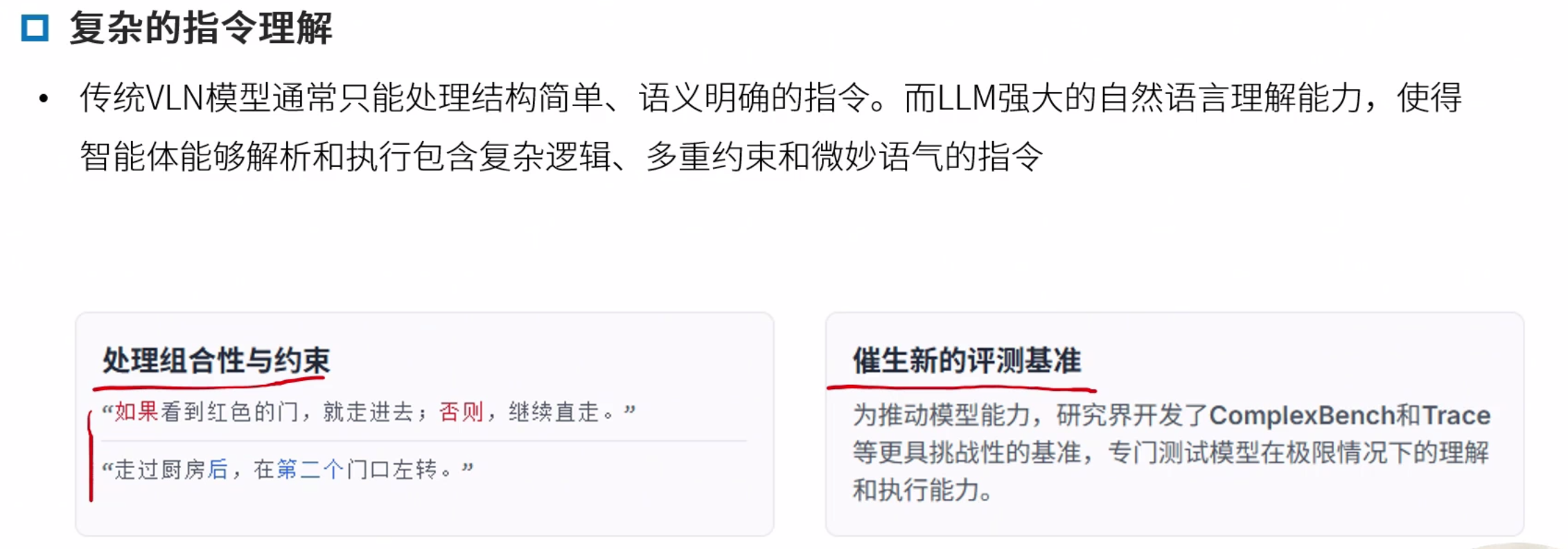


LLM
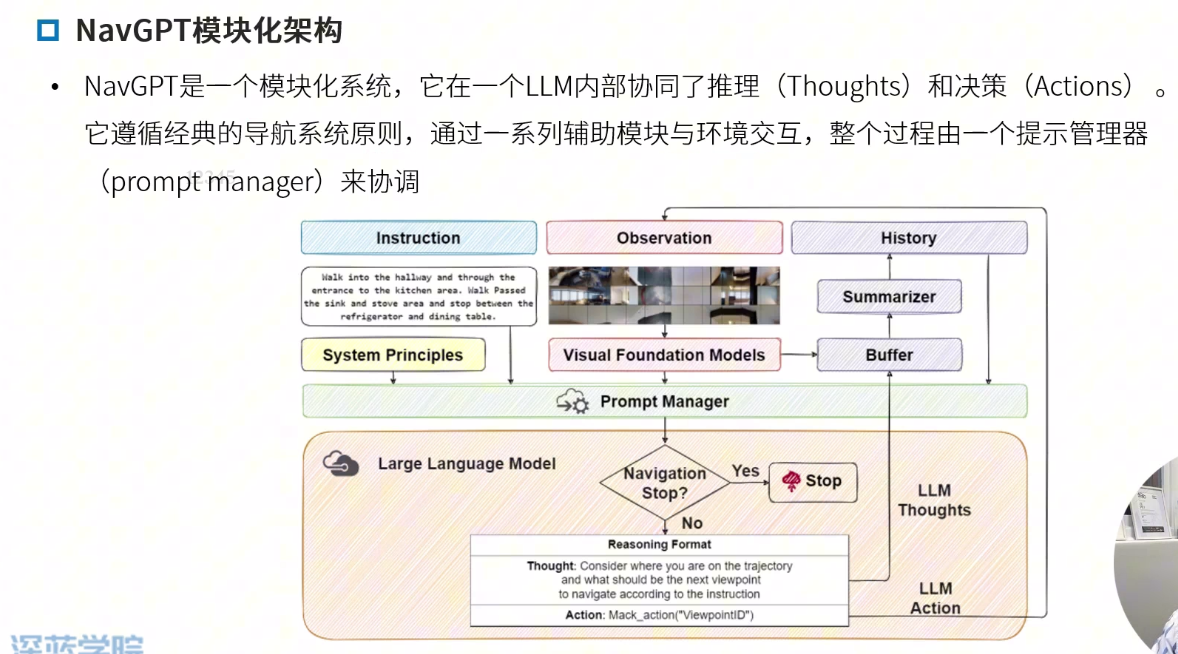
NavGPT
NavGPT: Explicit Reasoning in Vision-and-Language Navigation with Large Language Models


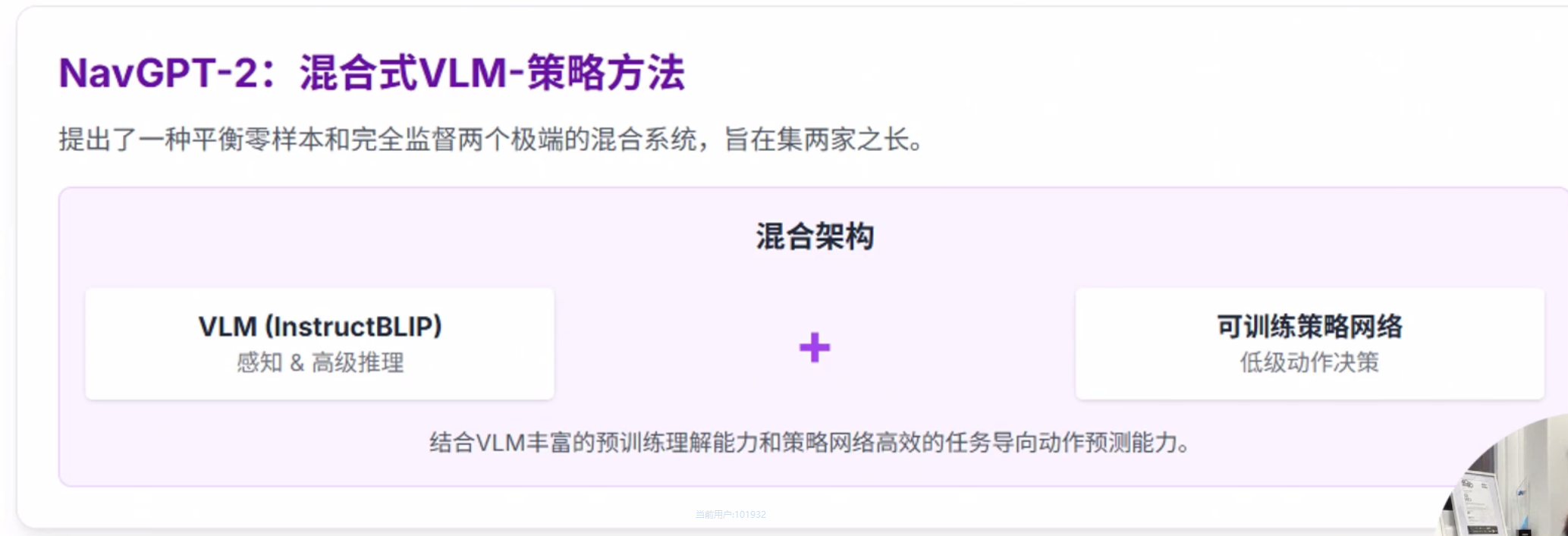
NavGPT-2
NavGPT-2: Unleashing Navigational Reasoning Capability for Large Vision-Language Models
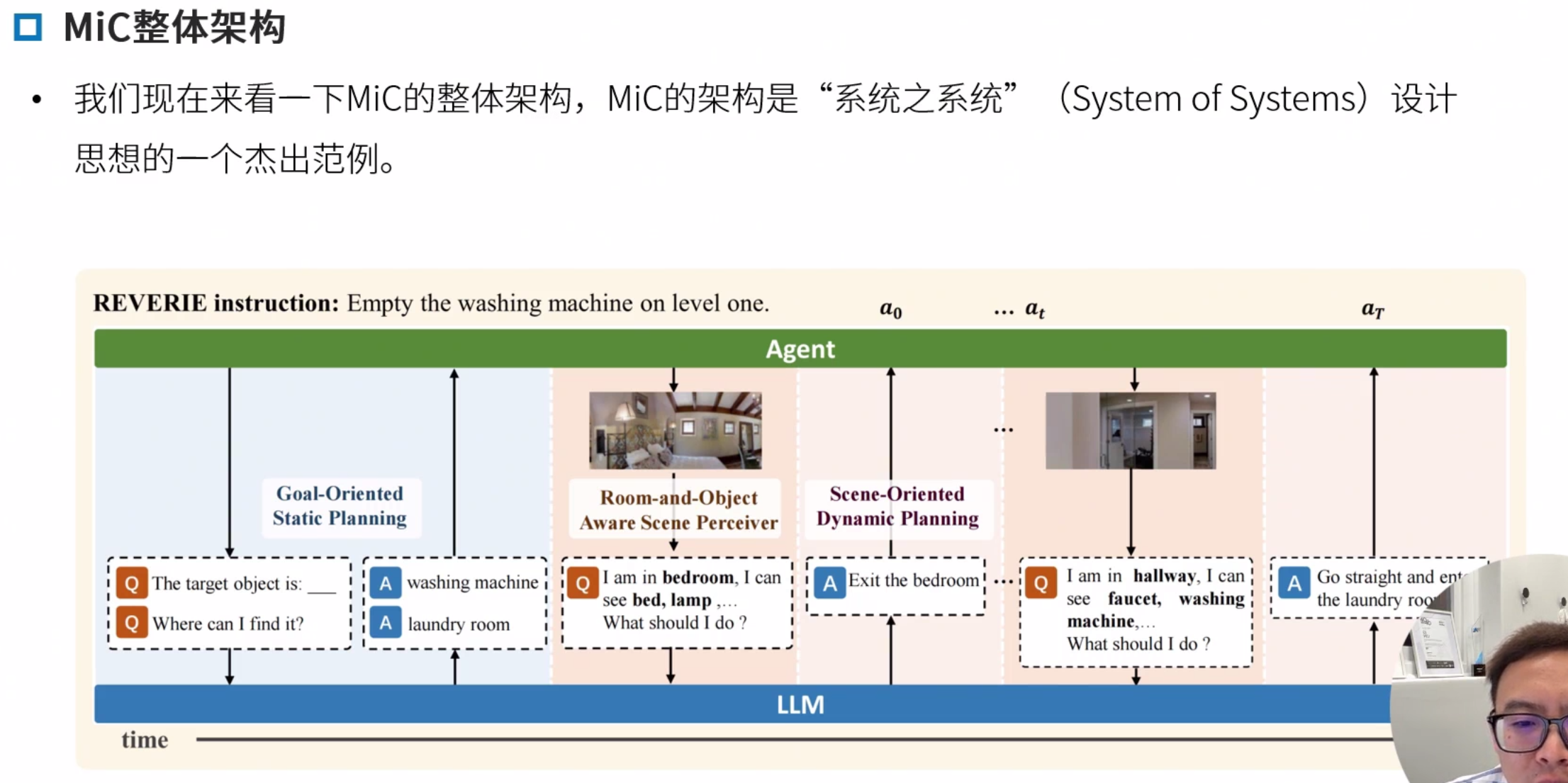
March in Chat (MiC)
March in Chat: Interactive Prompting for Remote Embodied Referring Expression



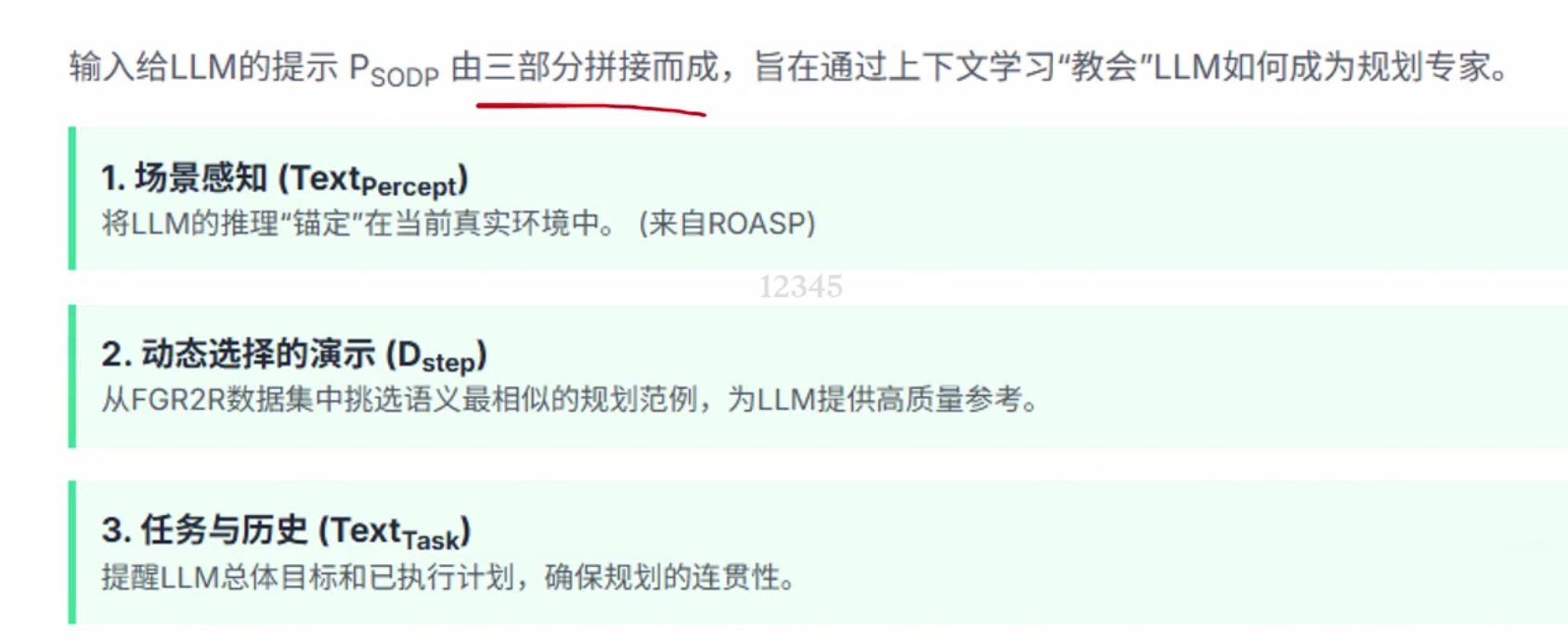
微调
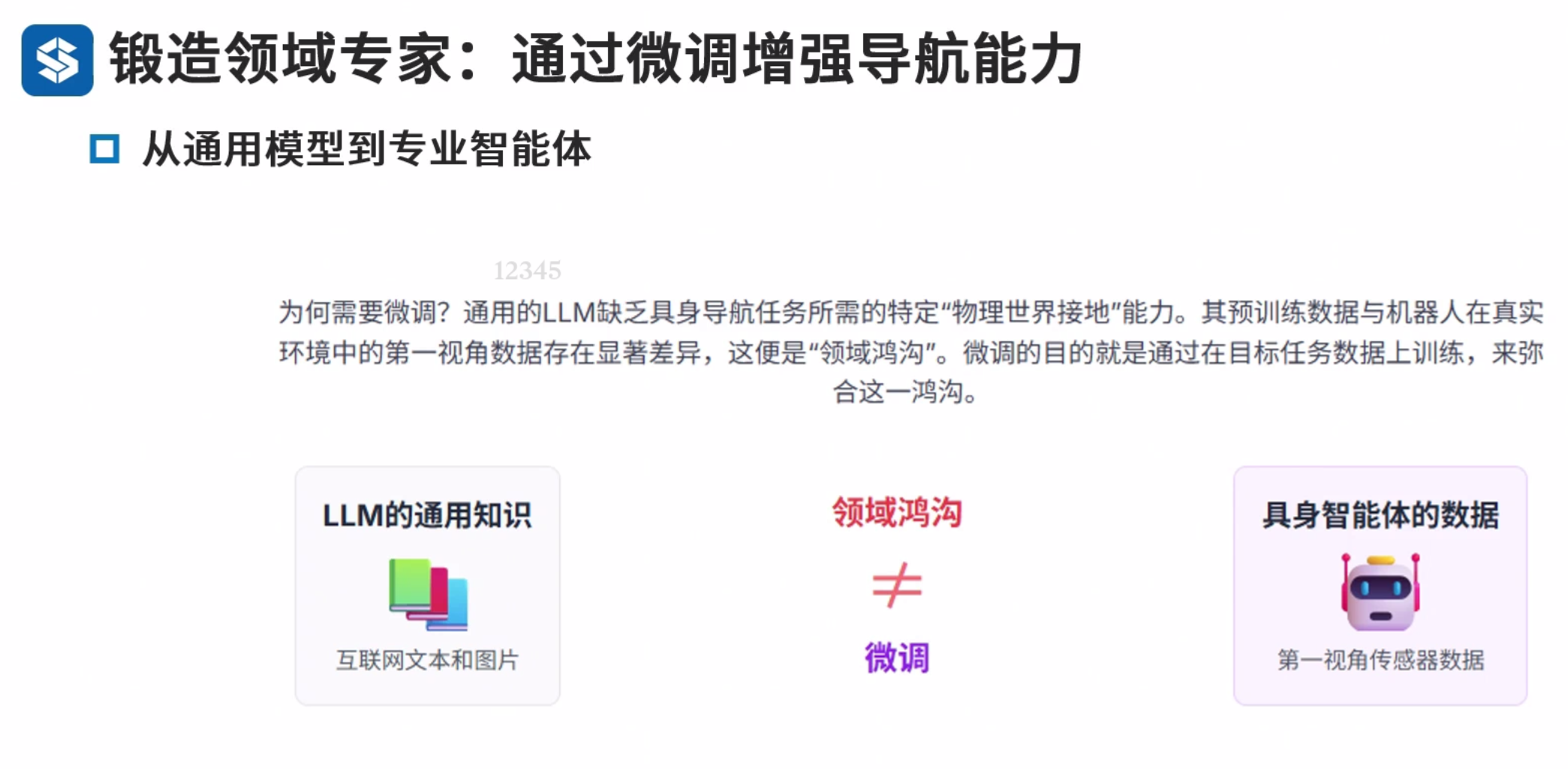
微调策略
PEFT LoRA

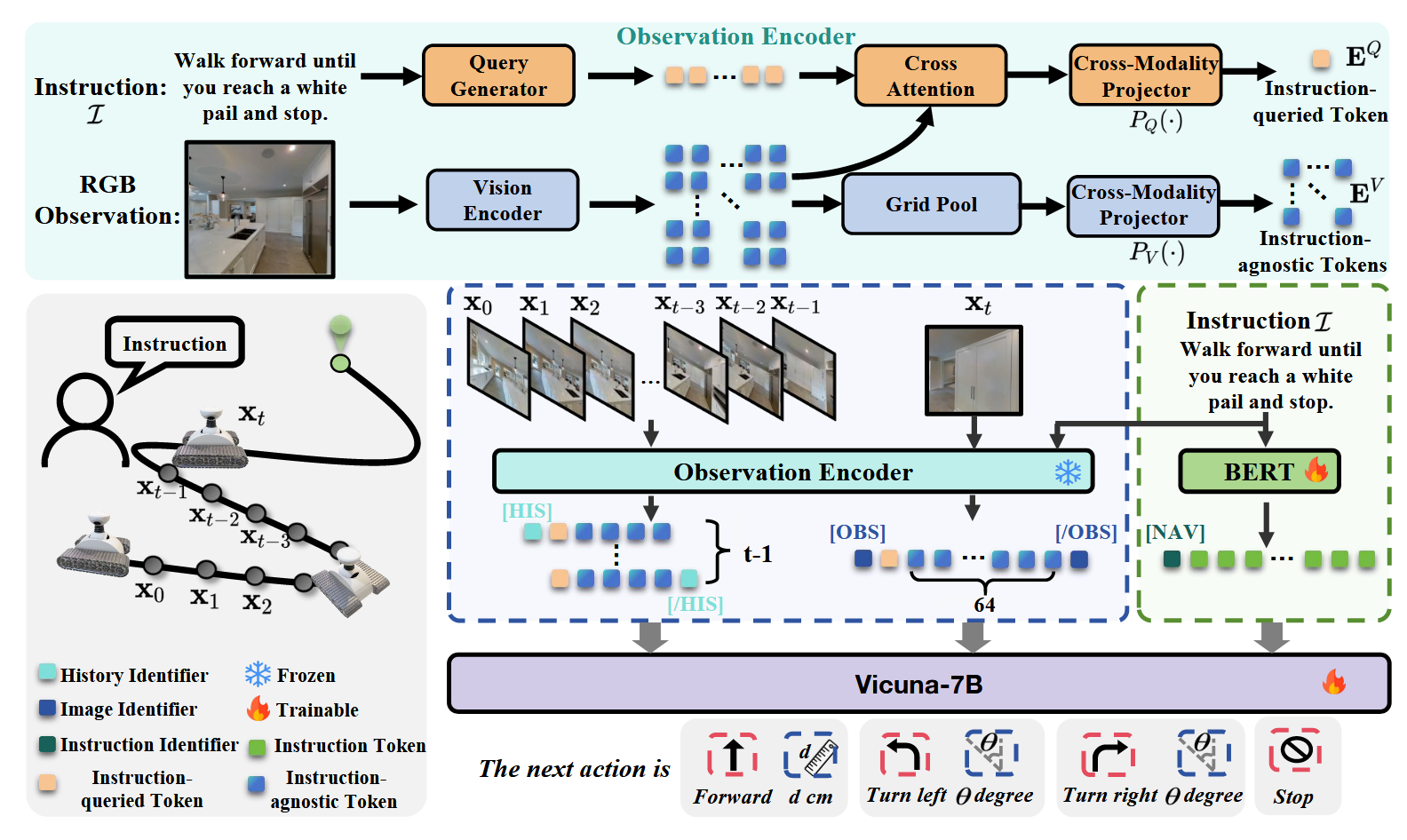
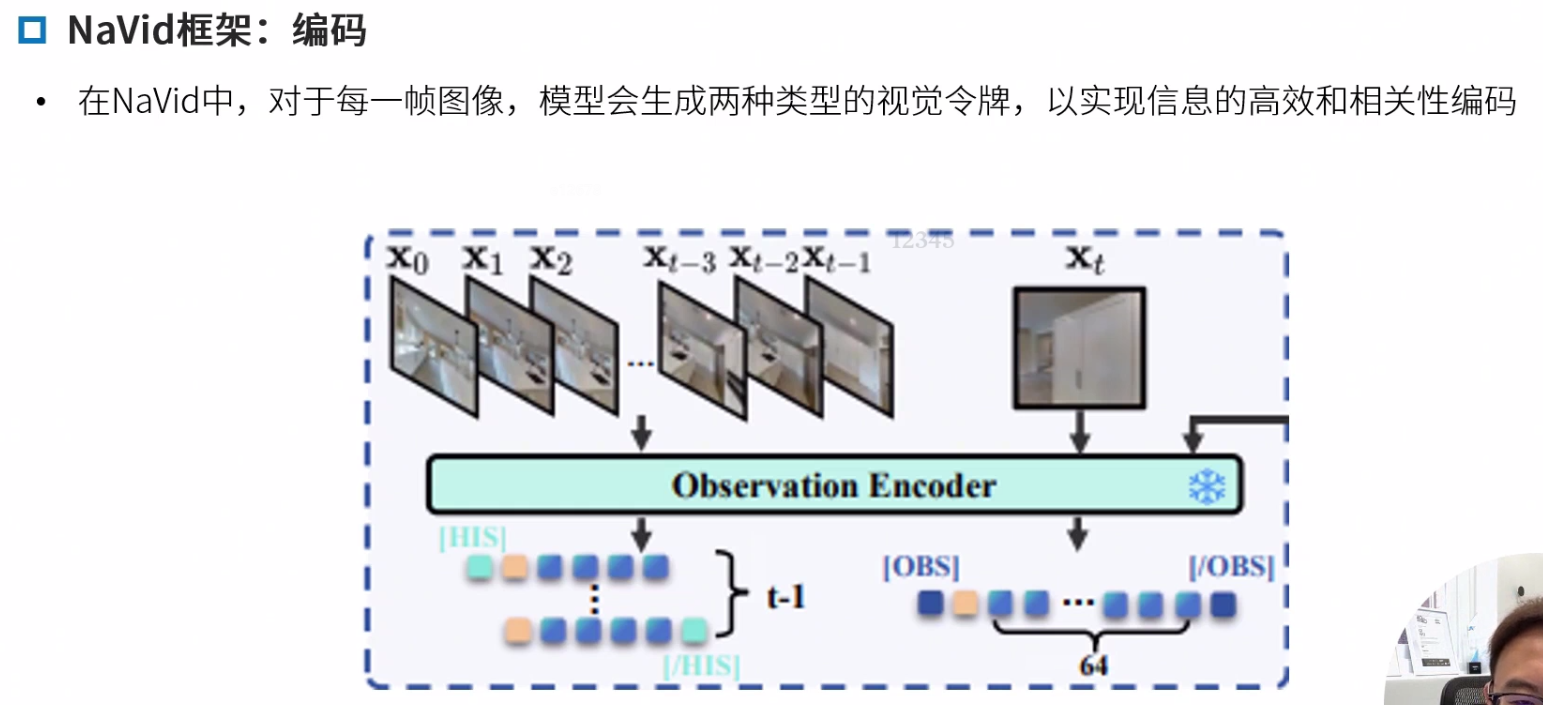
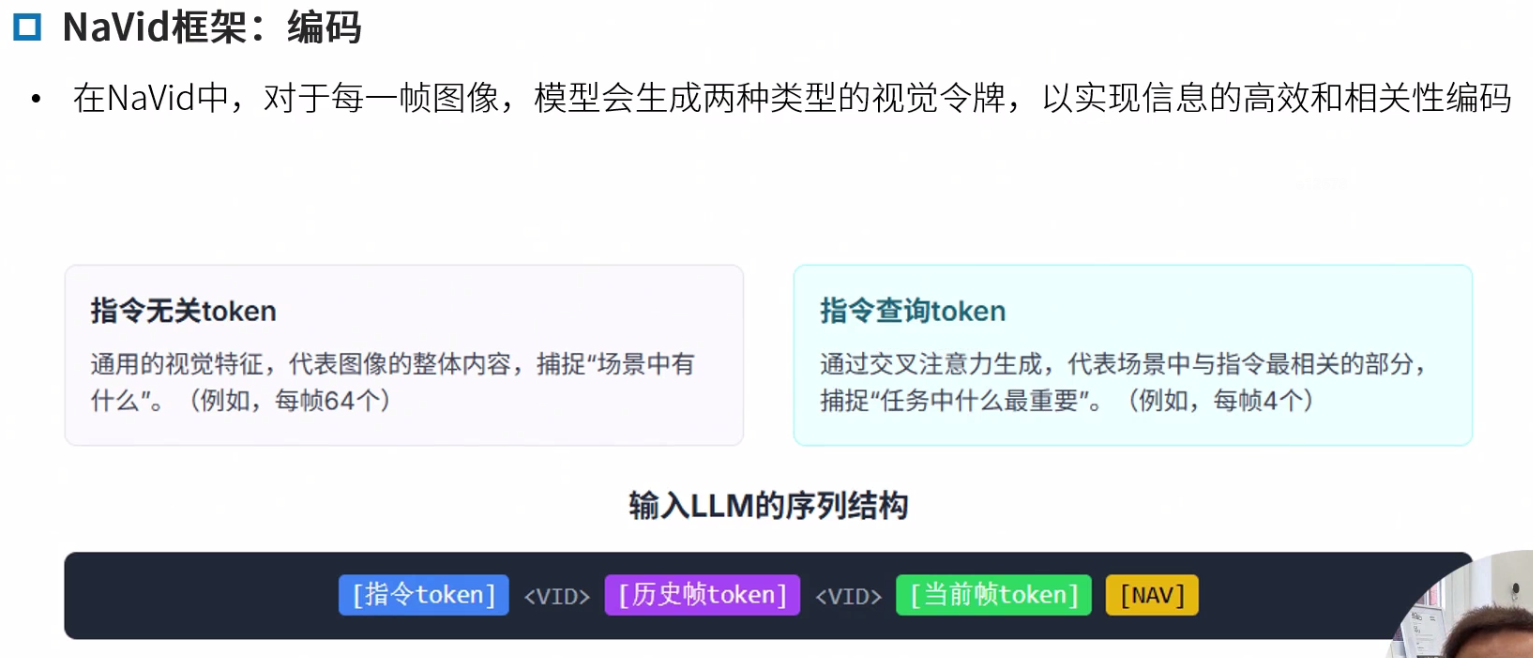
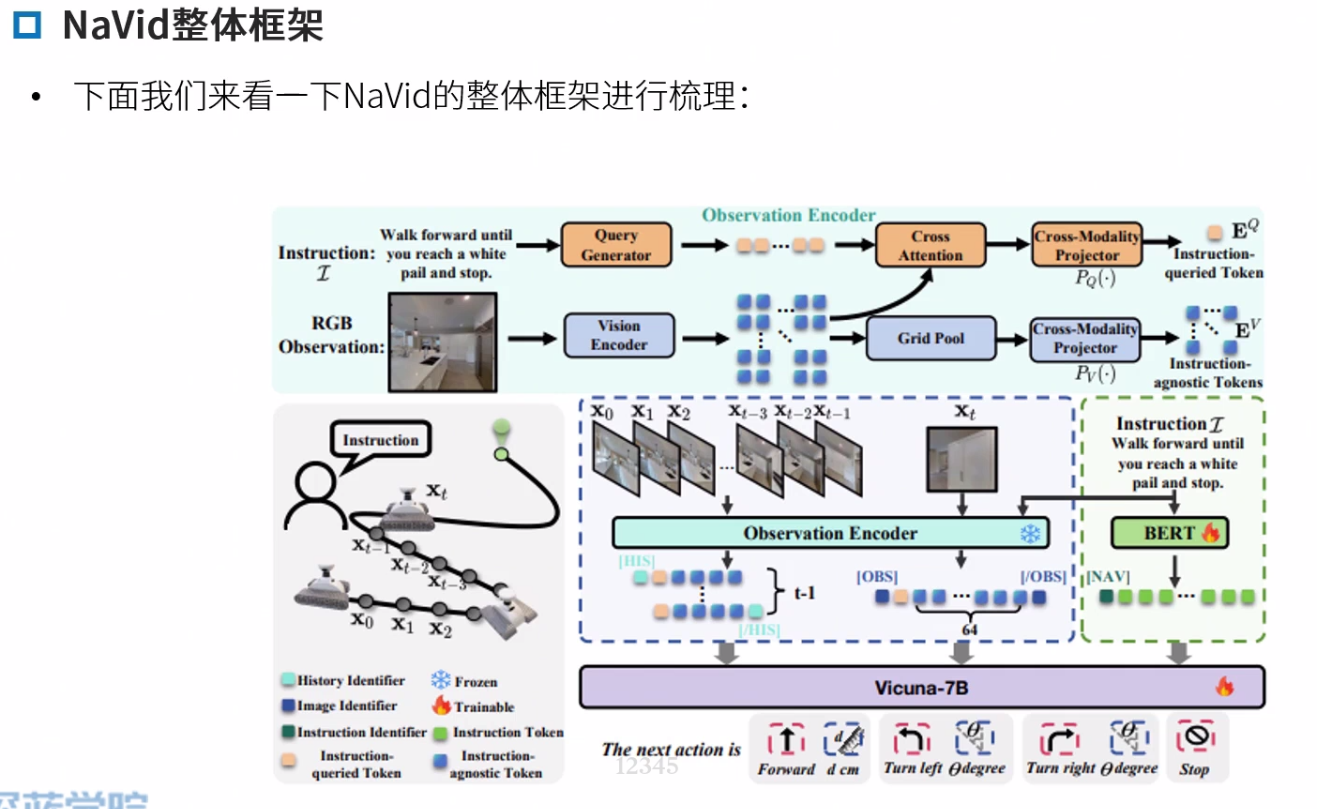
Navid框架
NaVid: Video-based VLM Plans the Next Step for Vision-and-Language Navigation
2024-05-28
 端到端的
端到端的
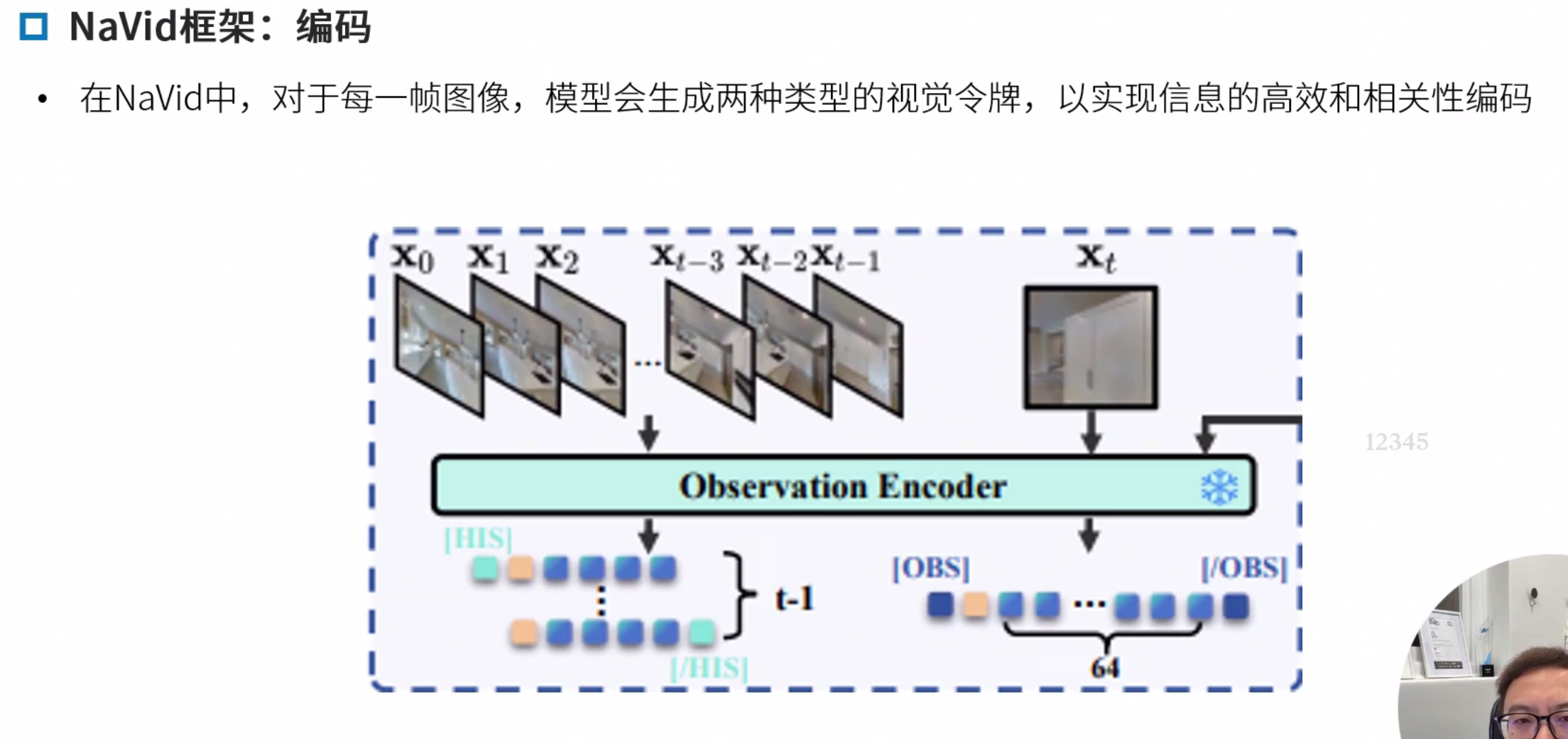
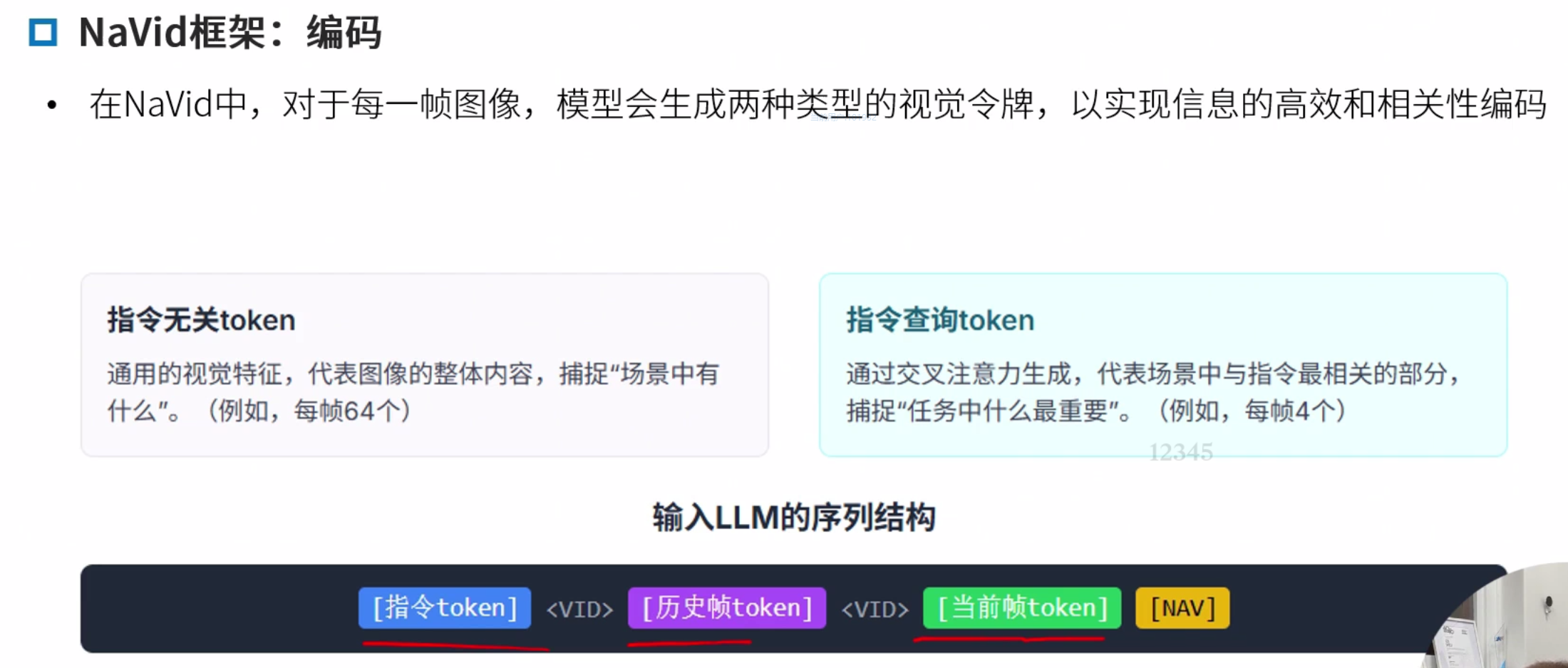
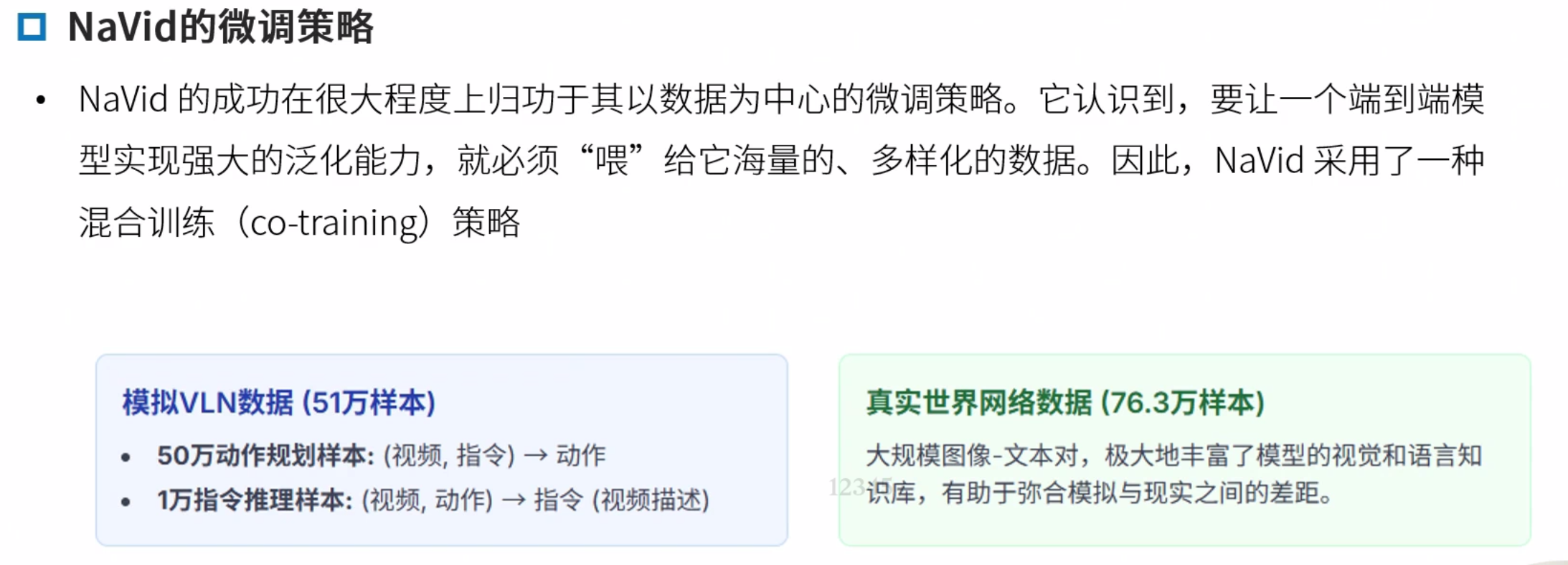
重点学习NaVid框架

数据集使用的是VLN-CE
LLM的挑战和总结
接地问题
抽象符号与物理数据感知 非具身的

幻觉问题
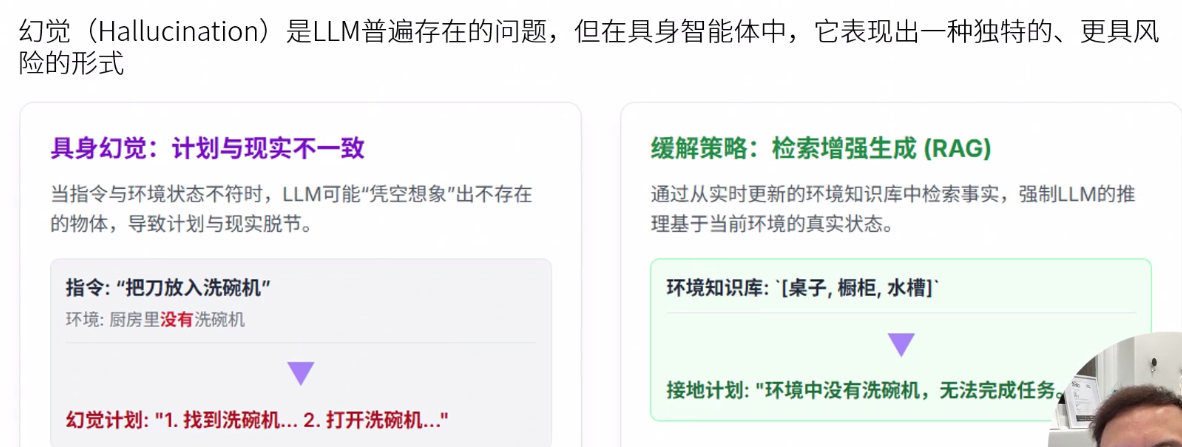
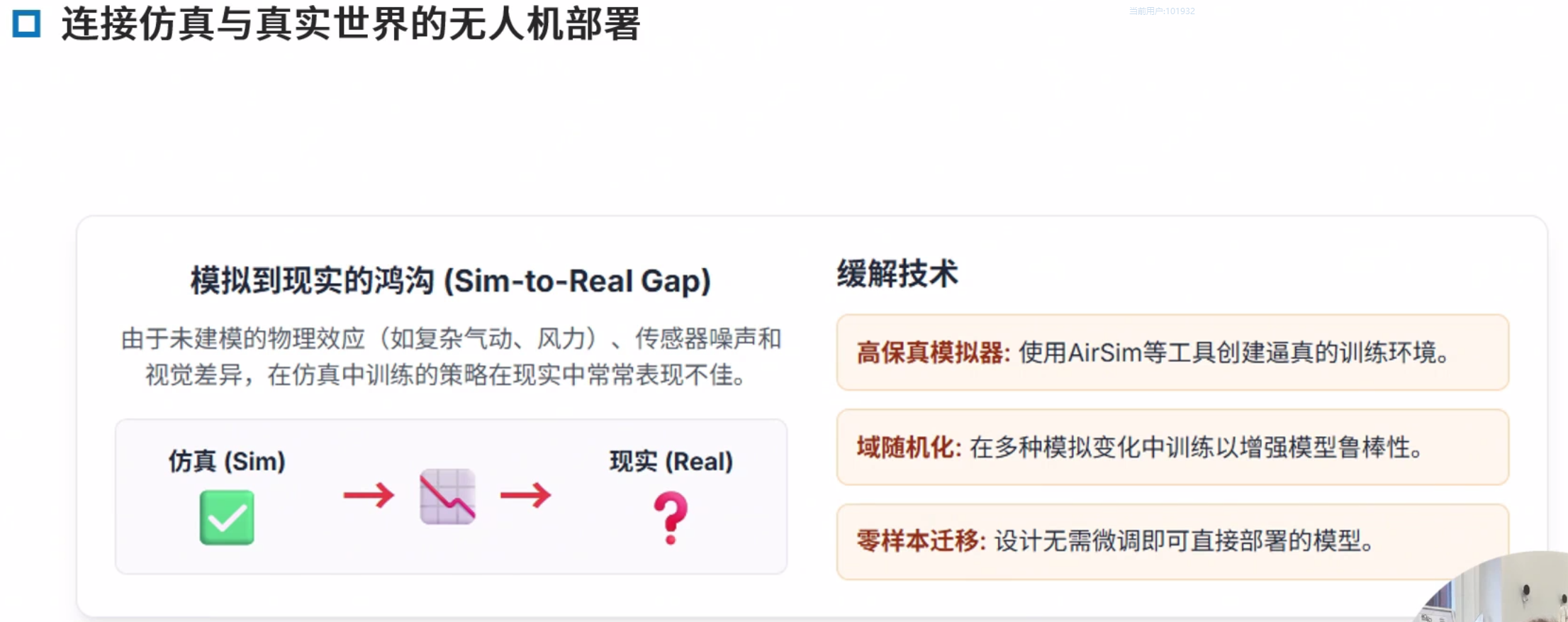
Sim2Real Gap

缺乏世界模型,只有相关性 没有因果性

未来应该 探索 世界模型,而不是仅仅增加数据和微调

第七章 Air VLN
空中的模型和思路会不一样
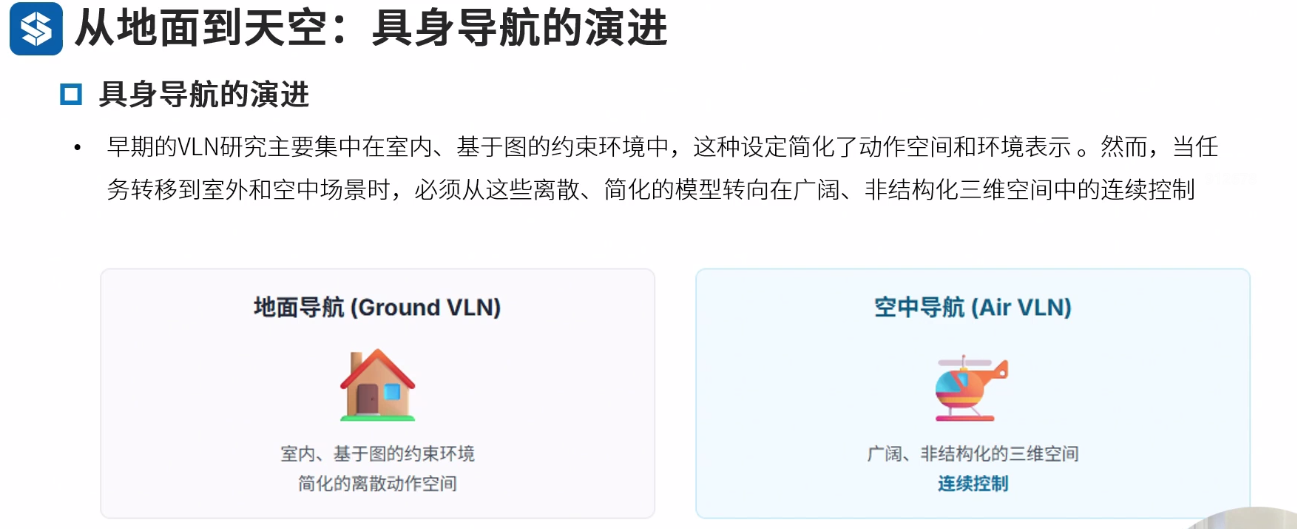
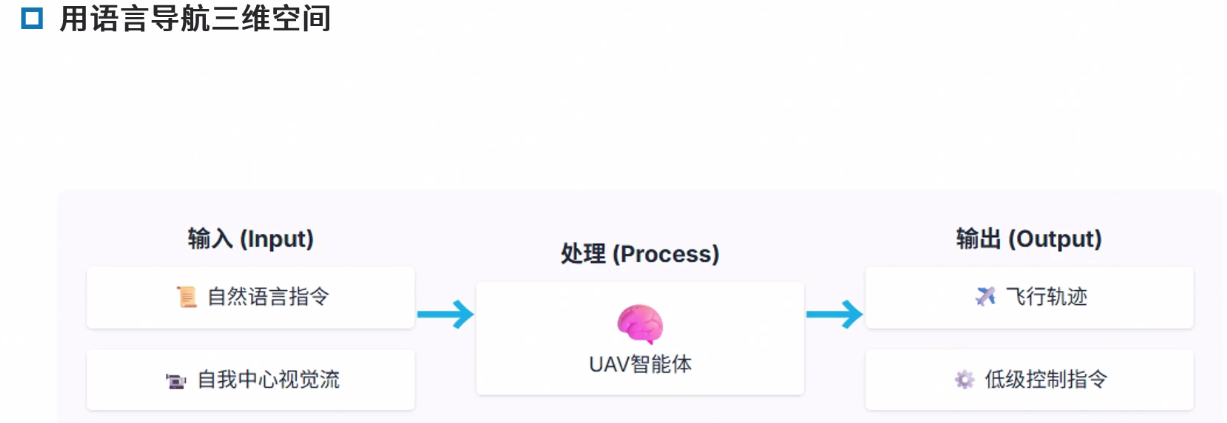

挑战
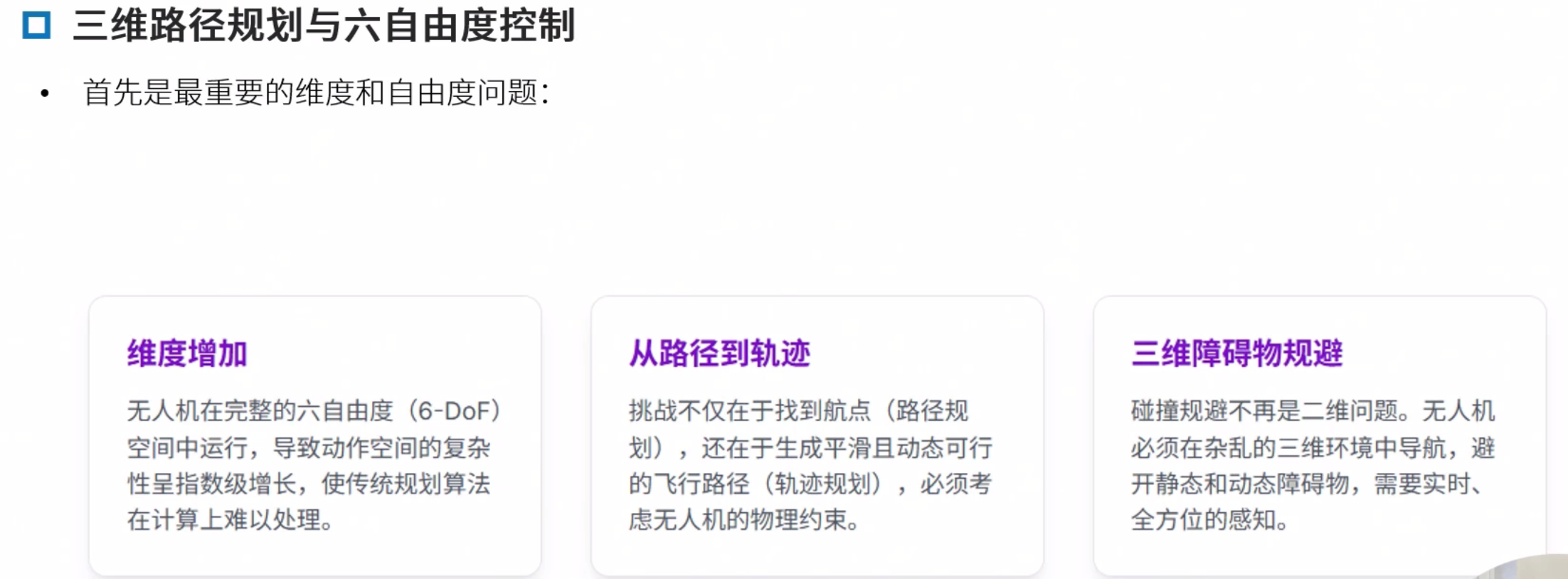
三维路径规划与自由度控制
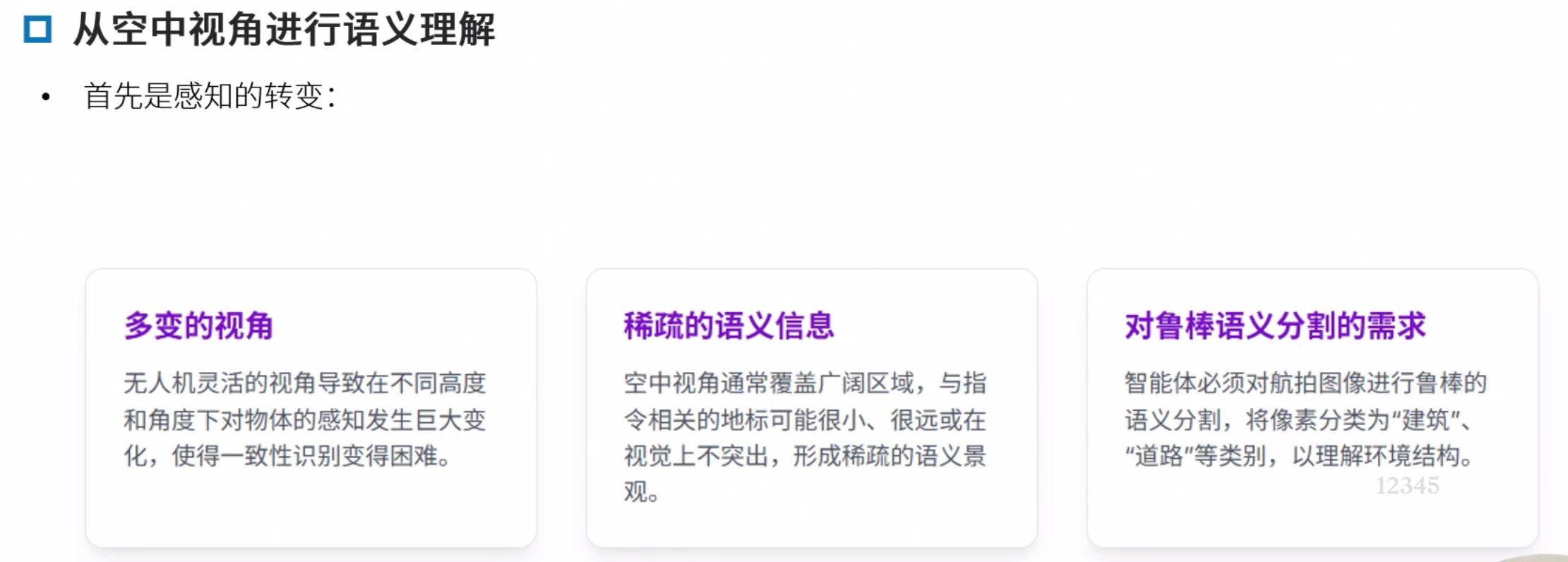
感知
Sim2Real

架构与模型
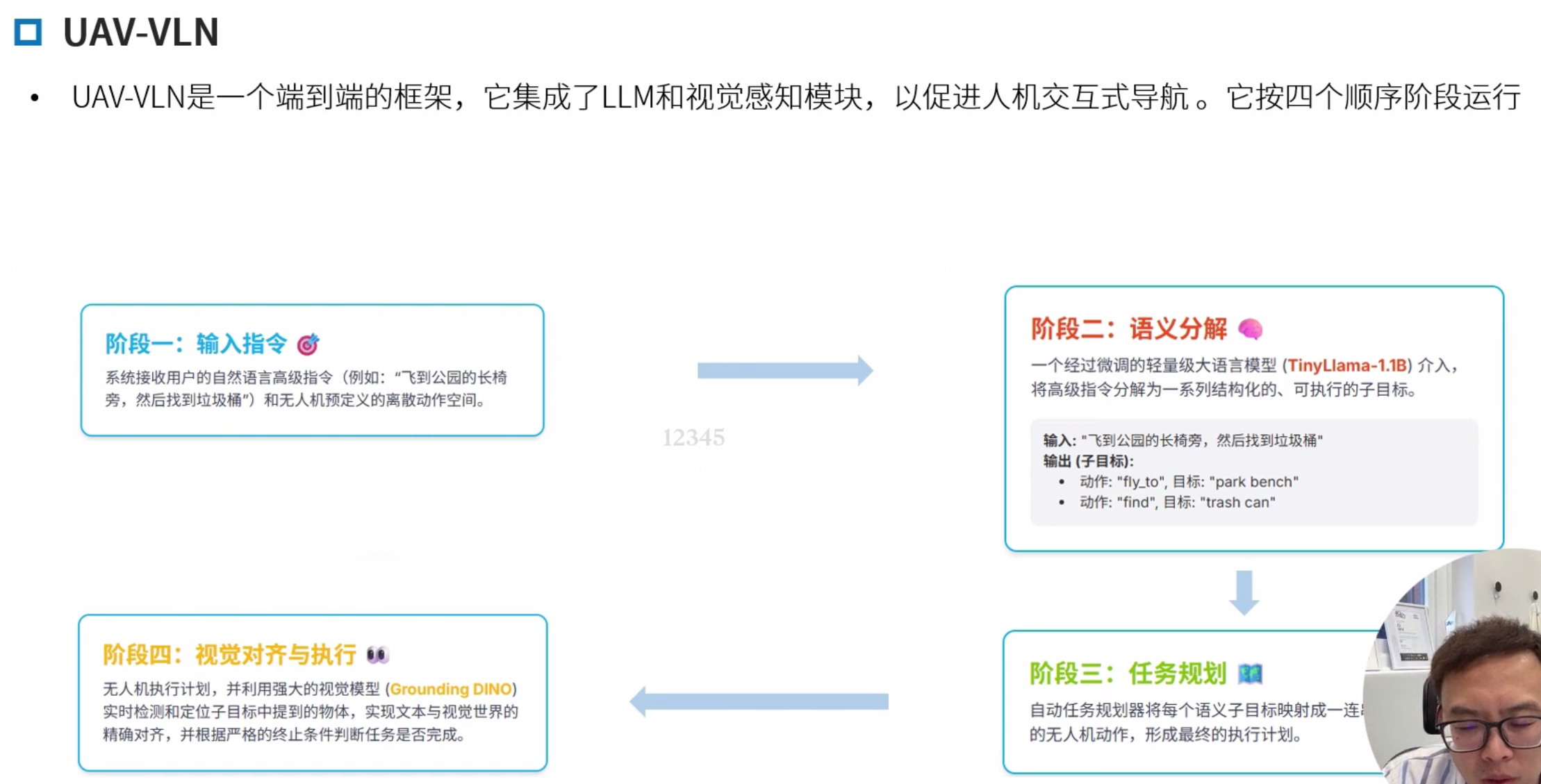
UAV-VLN
UAV-VLN: End-to-End Vision Language guided Navigation for UAVs
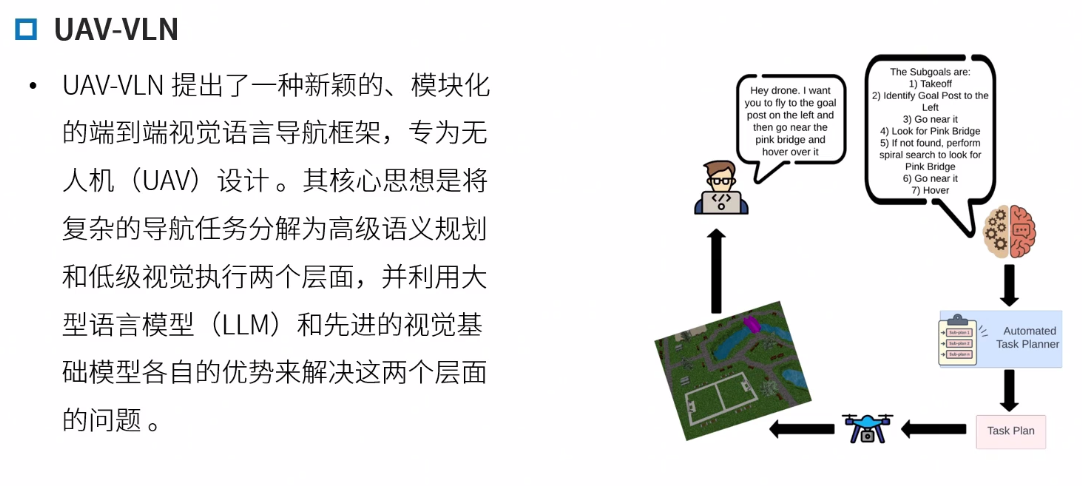
端到端框架 四个步骤 预定义的离散的动作空间

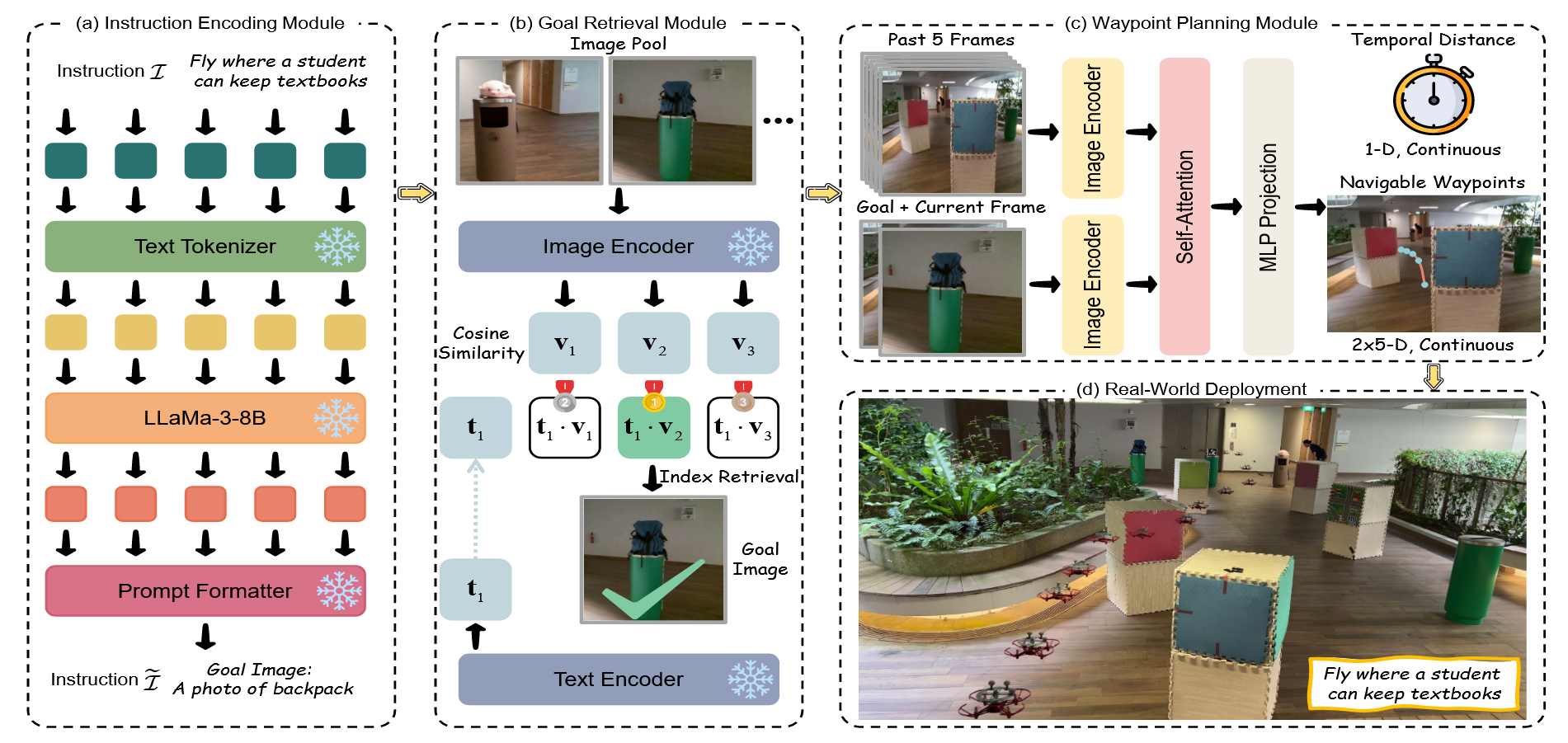
VLFly
Grounded Vision-Language Navigation for UAVs with Open-Vocabulary Goal Understanding
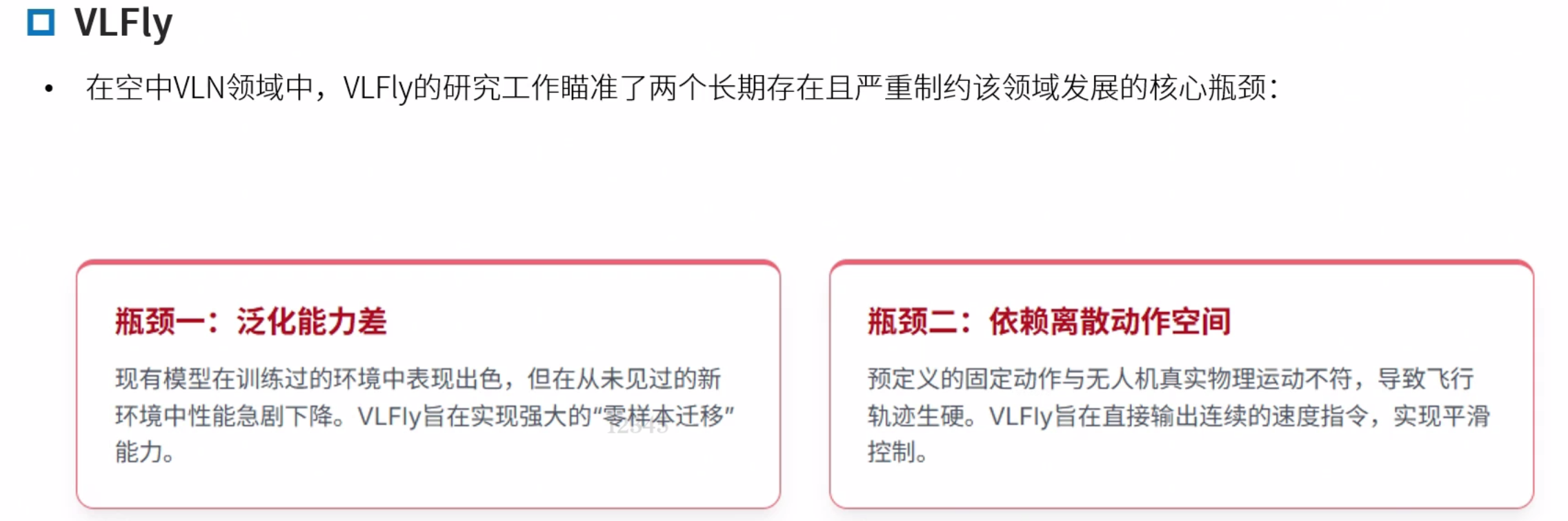
模块化的架构

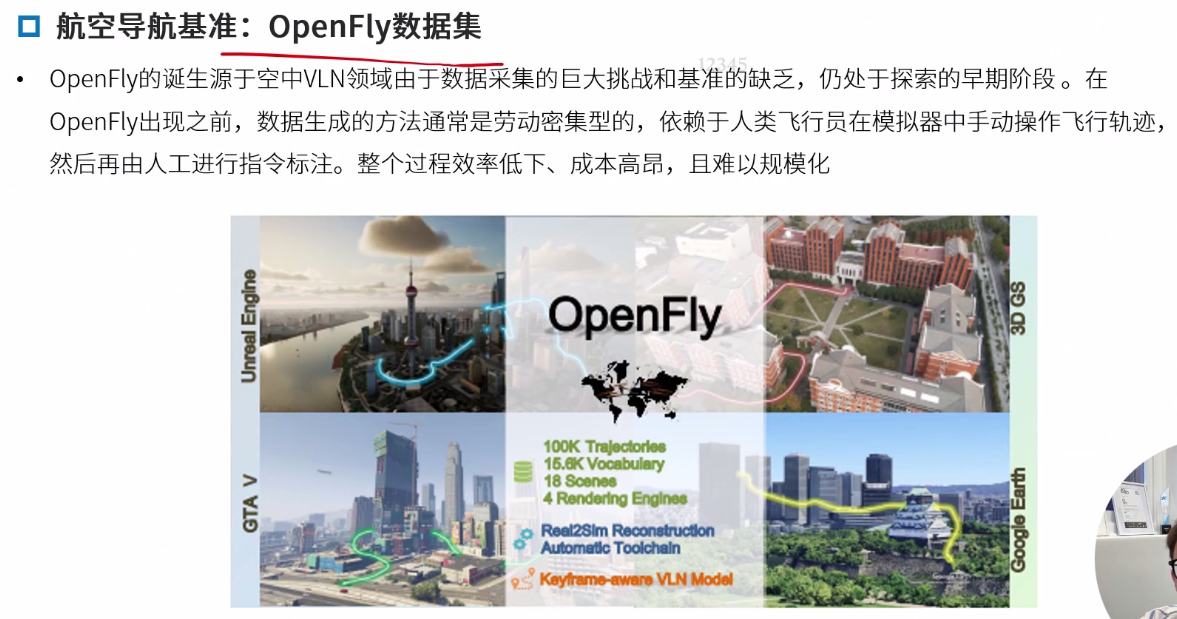
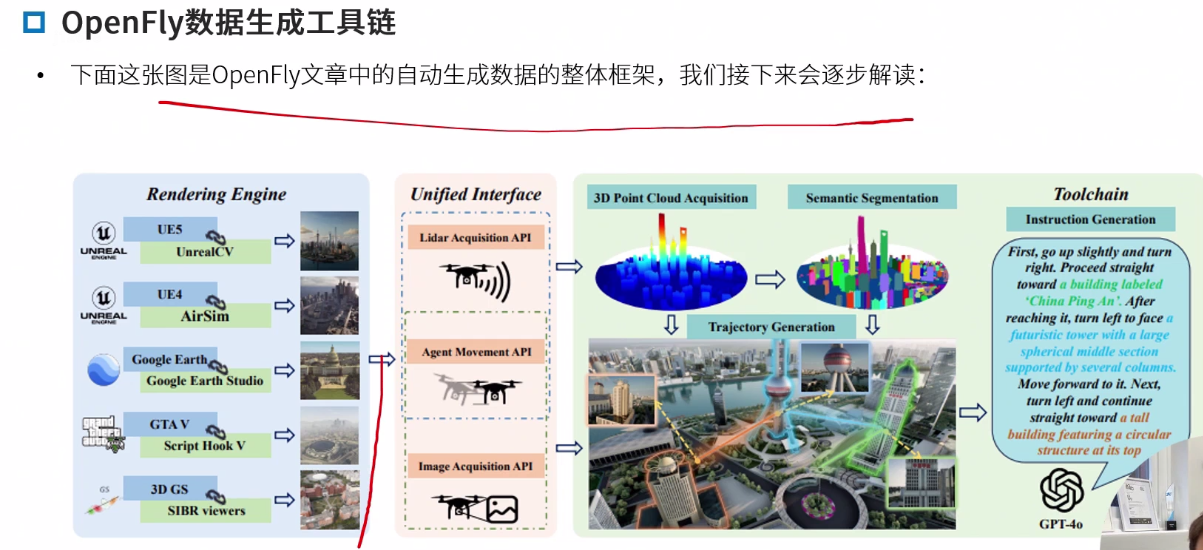
OpenFly
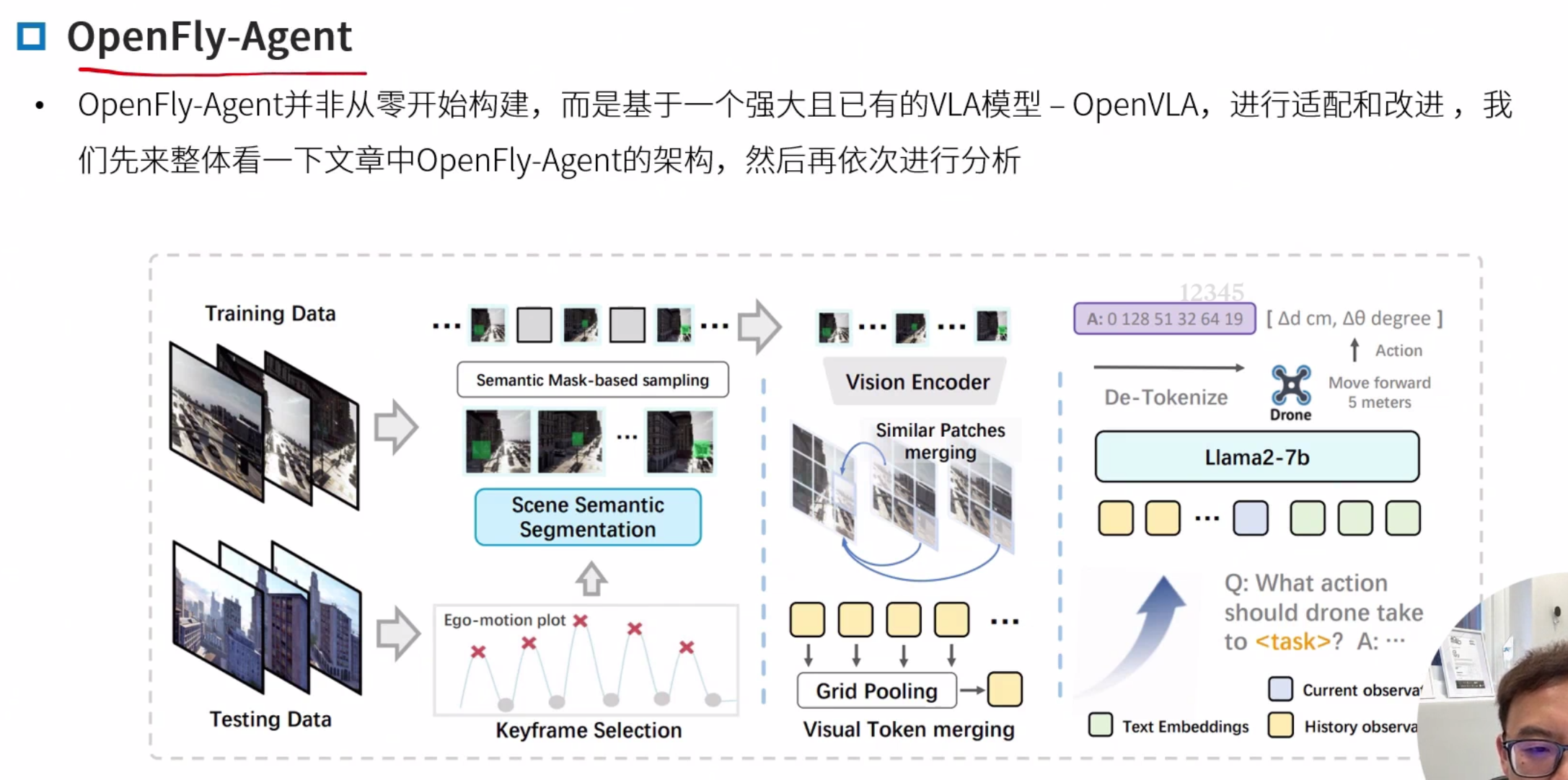
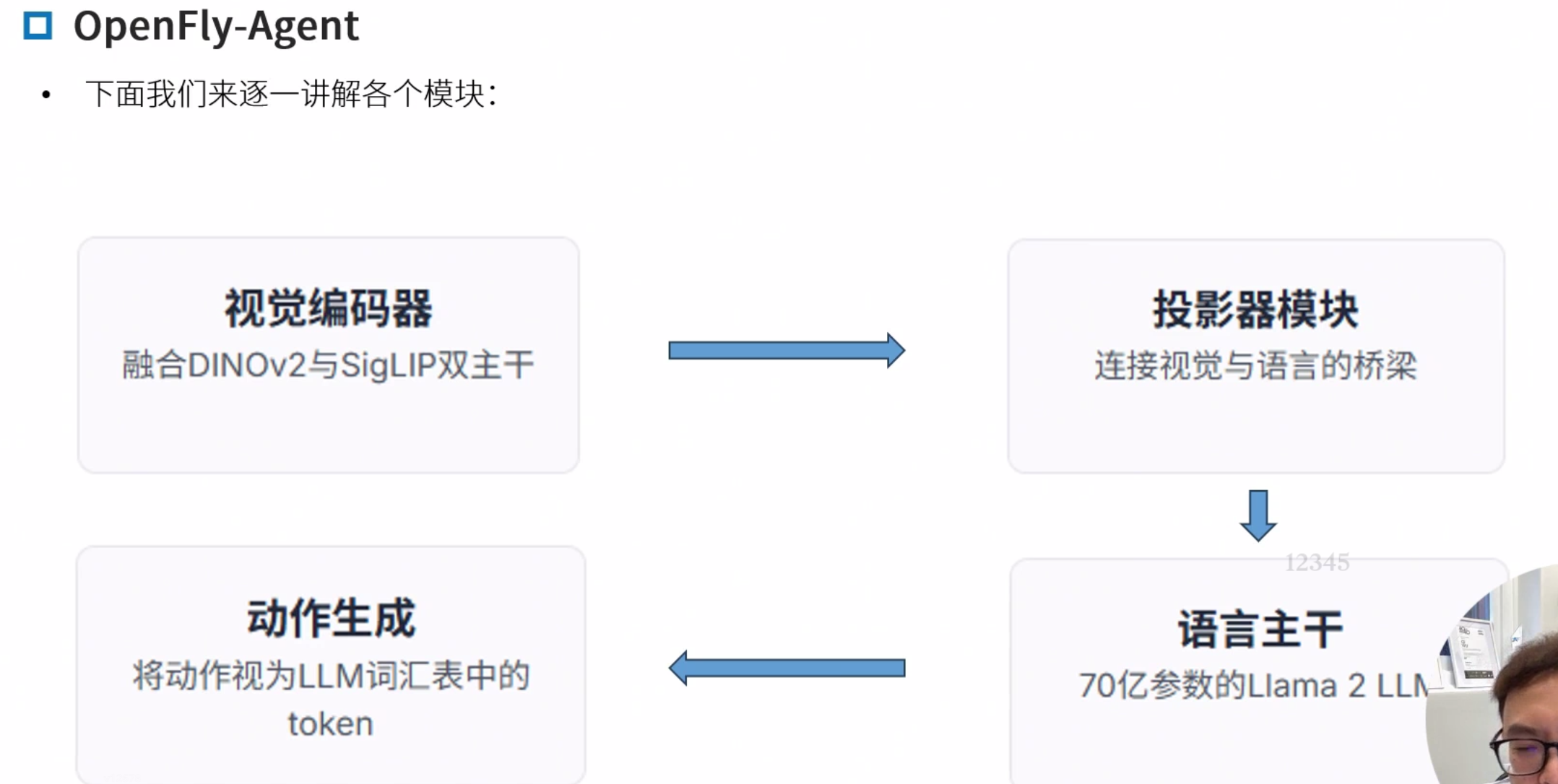
OpenFly-Agent
OpenFly: A Comprehensive Platform for Aerial Vision-Language Navigation
基于OpenVLA
Air VLN的生态
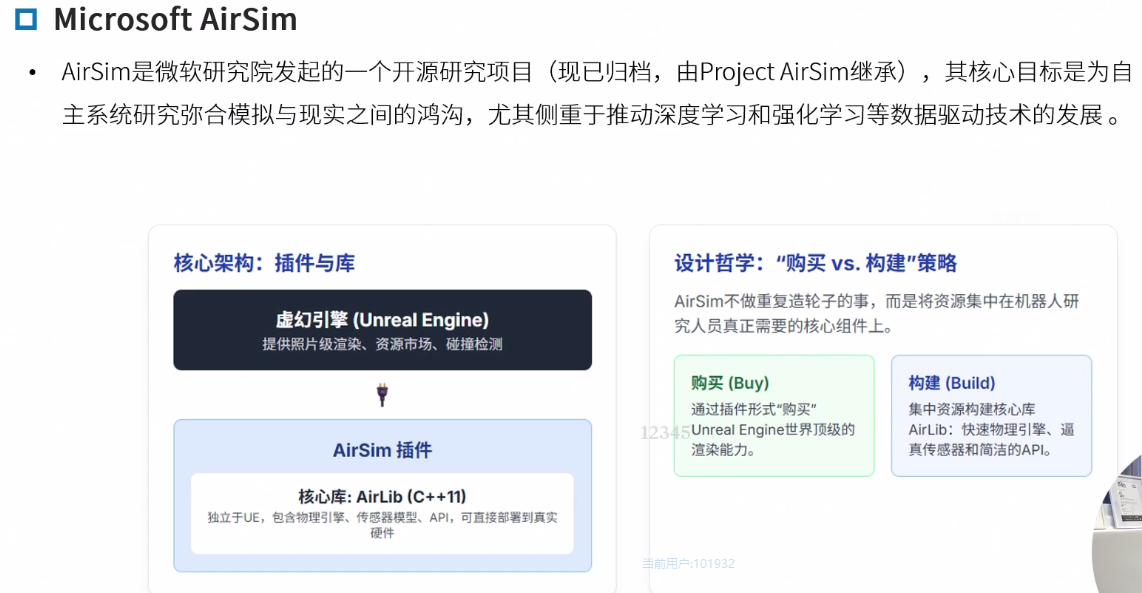
AirSim

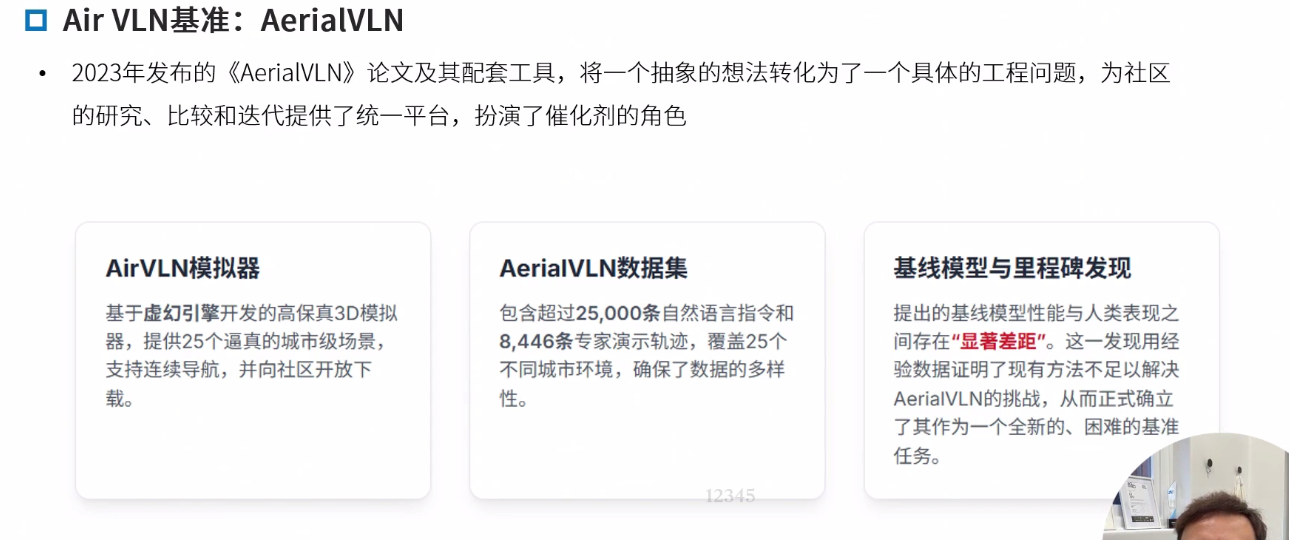
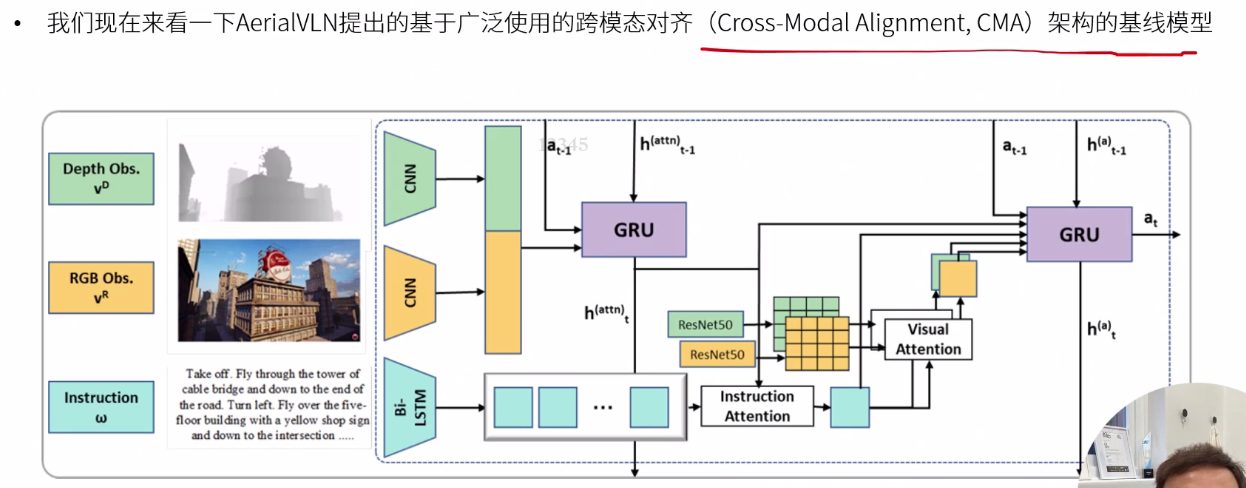
AerialVLN
AerialVLN: Vision-and-Language Navigation for UAVs

OpenFly
OpenFly: A Comprehensive Platform for Aerial Vision-Language Navigation
不仅是数据集,还有生态


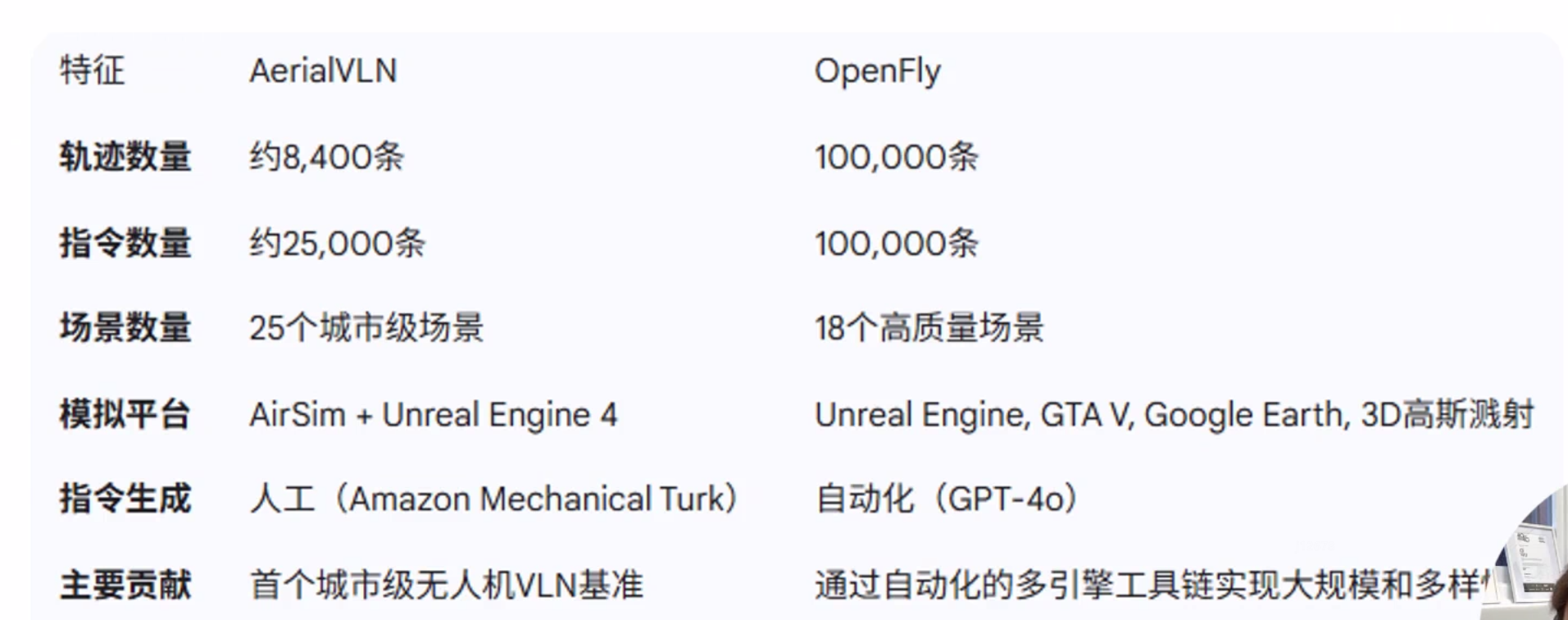
AerialVLN vs OpenFly
第八章 机器人中的视觉语言导航应用
仿真到物理世界

显著的性能下降

鸿沟解构
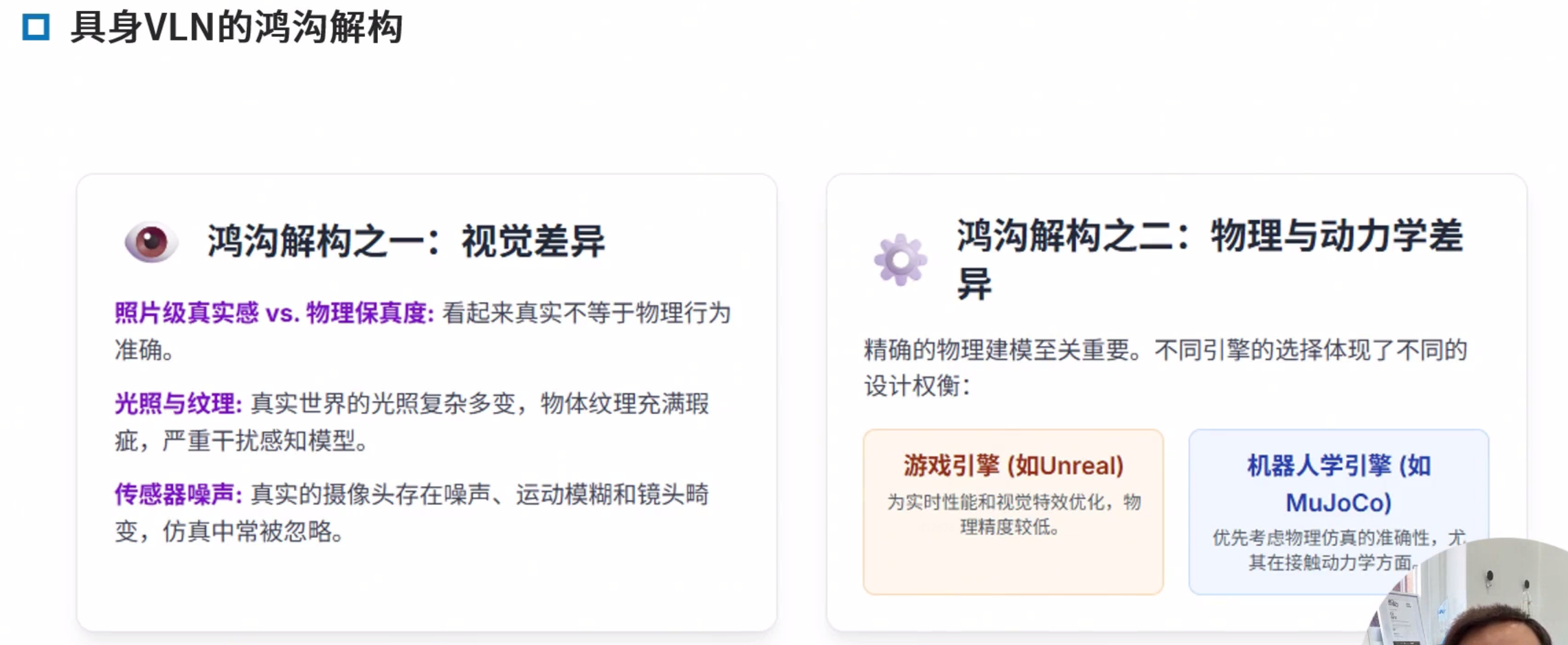

分层,高层推理,底层执行
弥合鸿沟
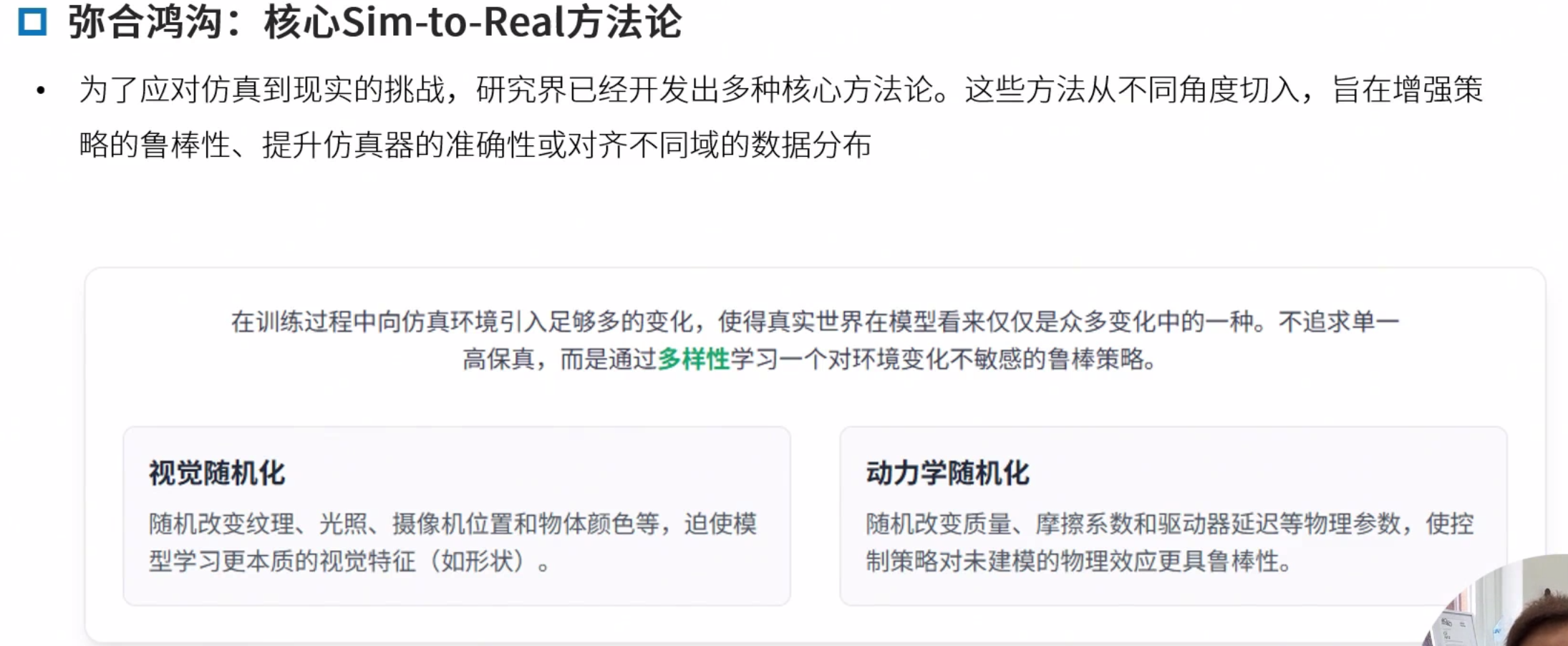
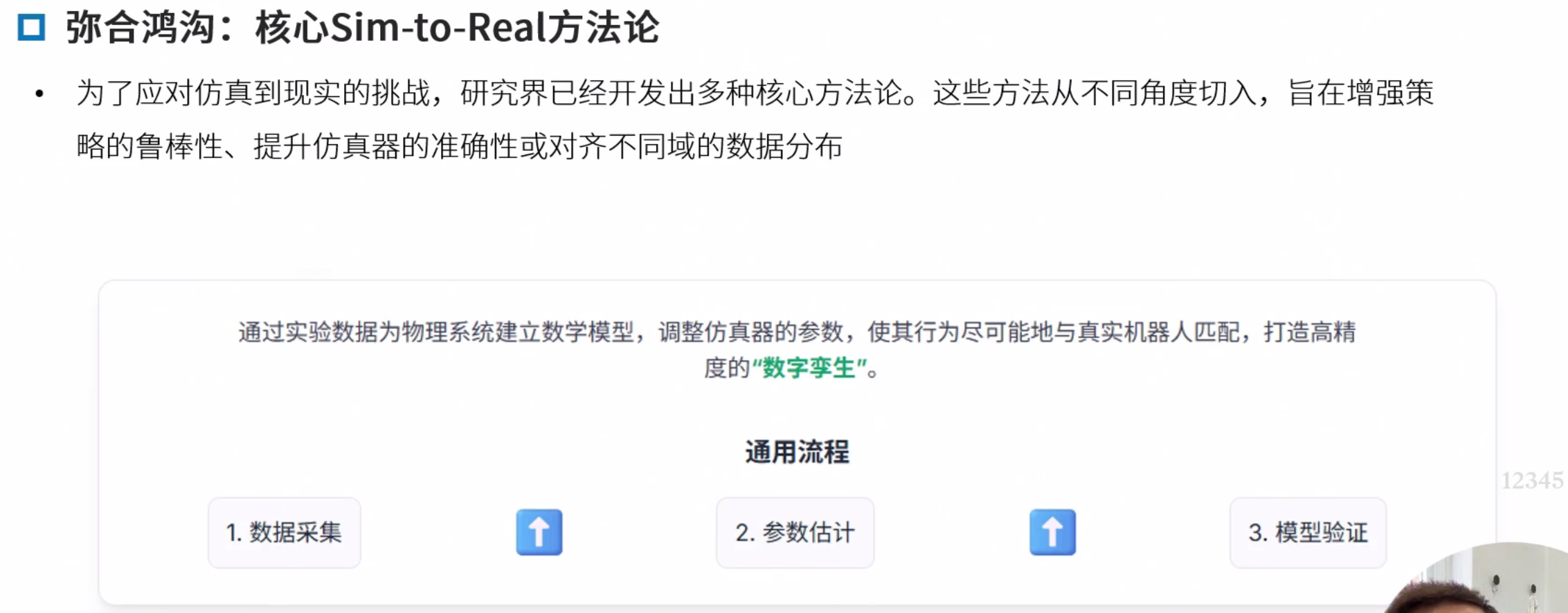
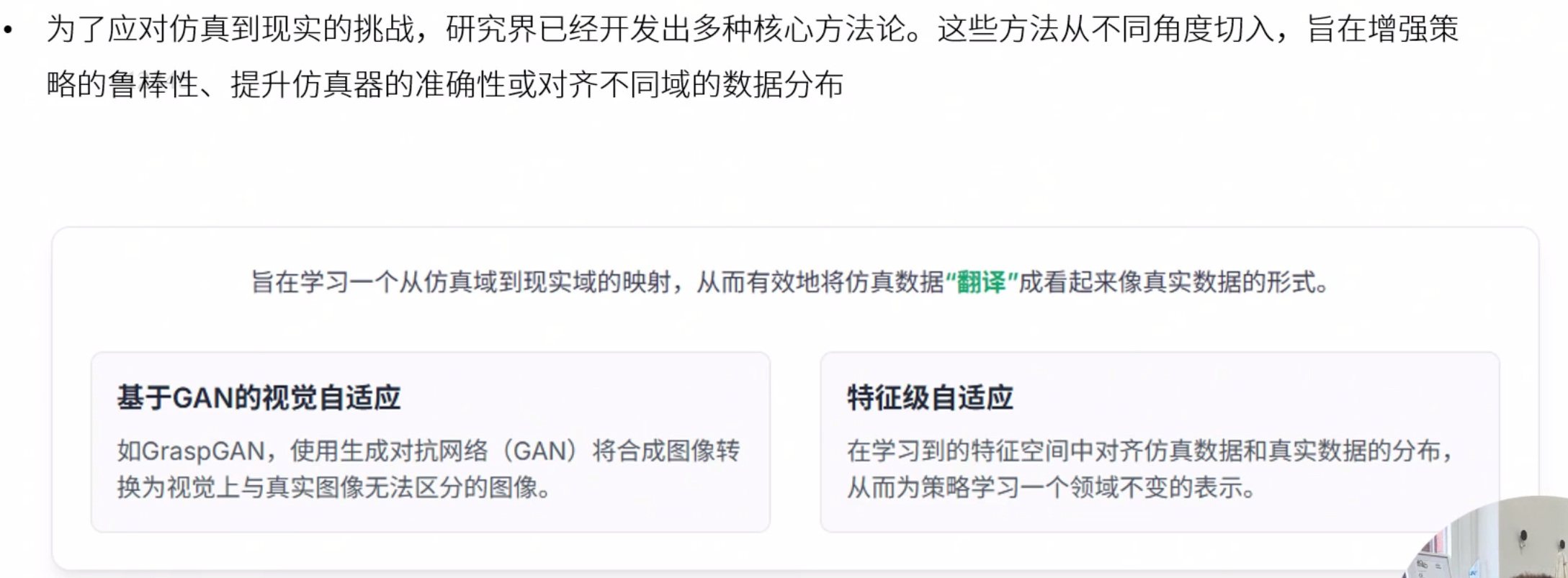

前沿架构
主要框架案例

GVNav
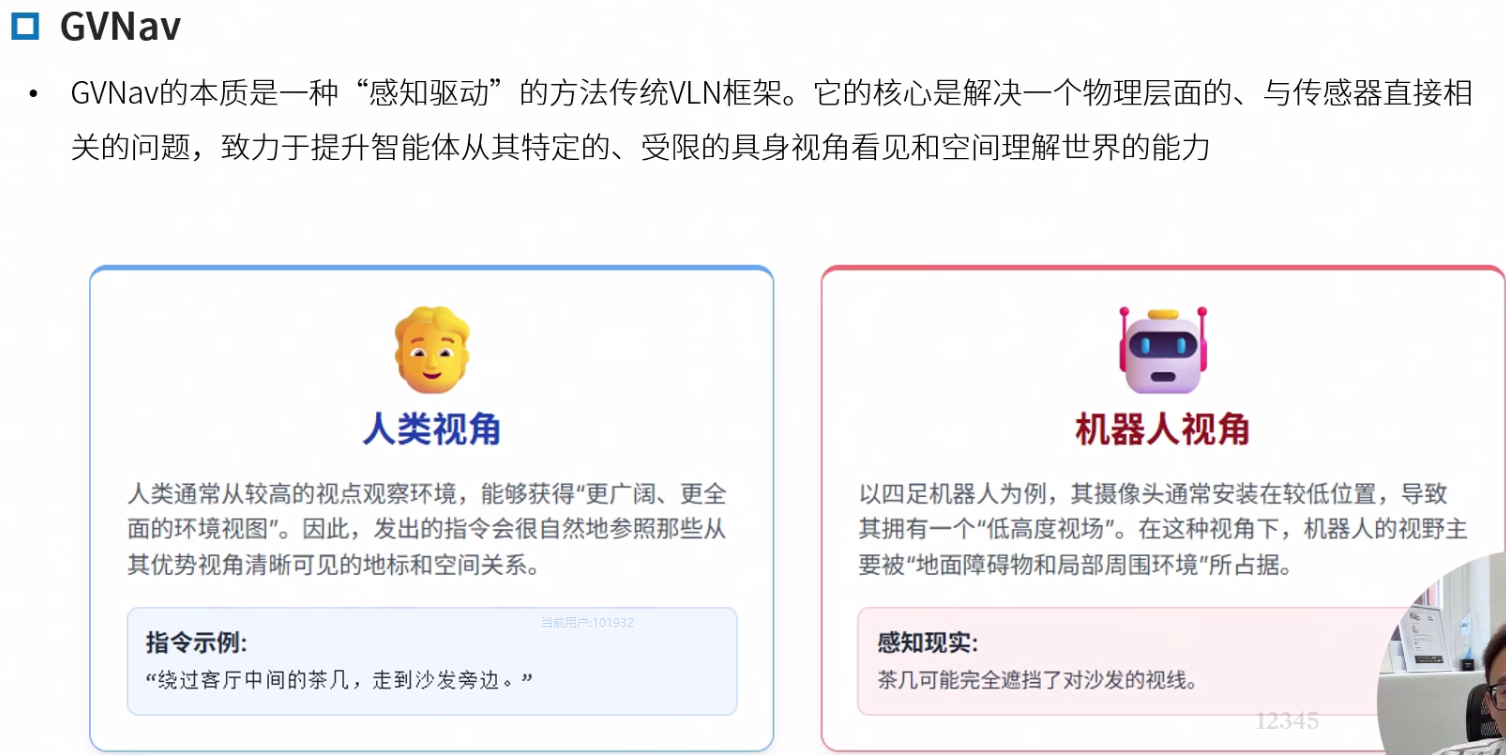
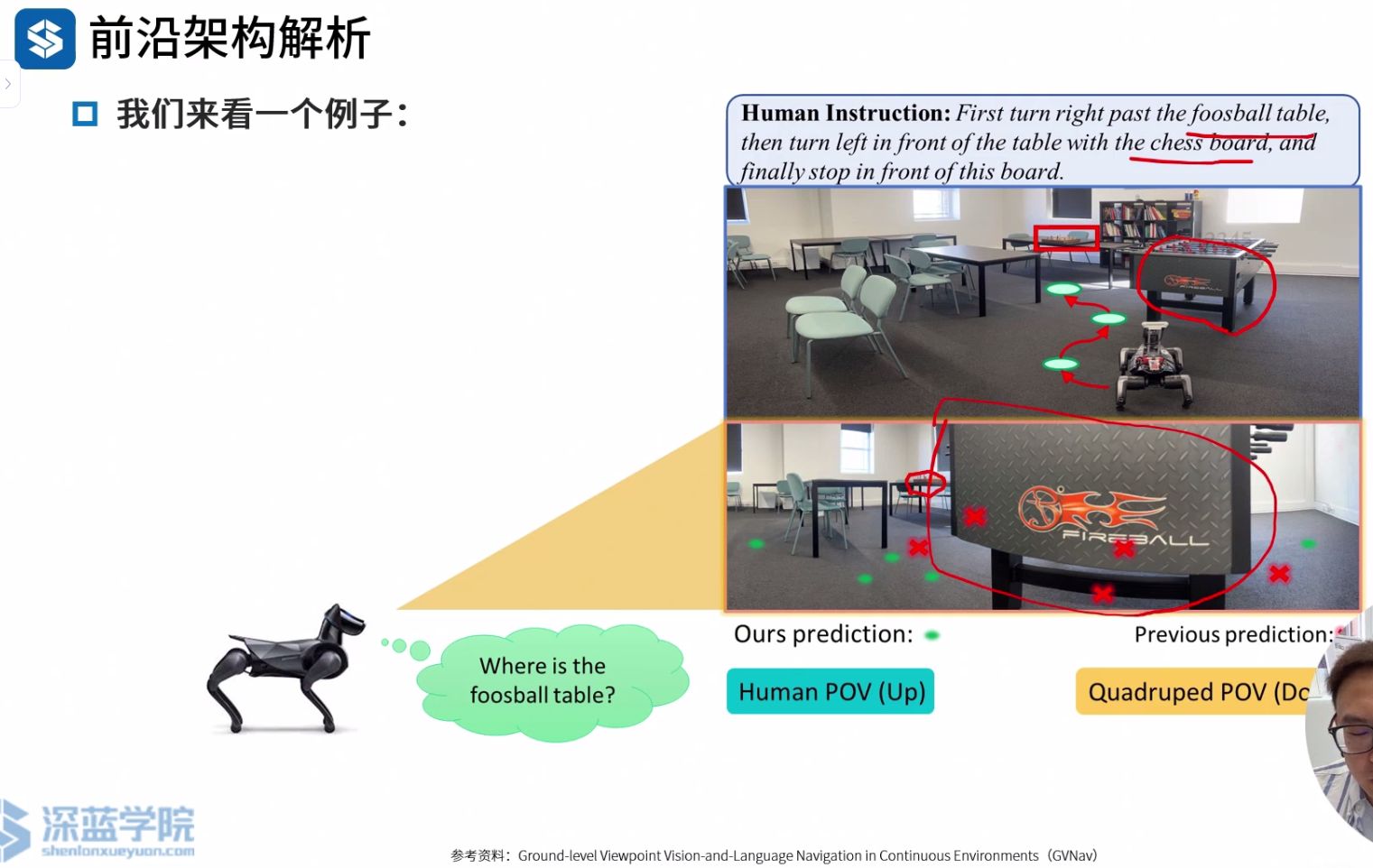
物理高度导致的视点不匹配问题,引发连锁性的失败

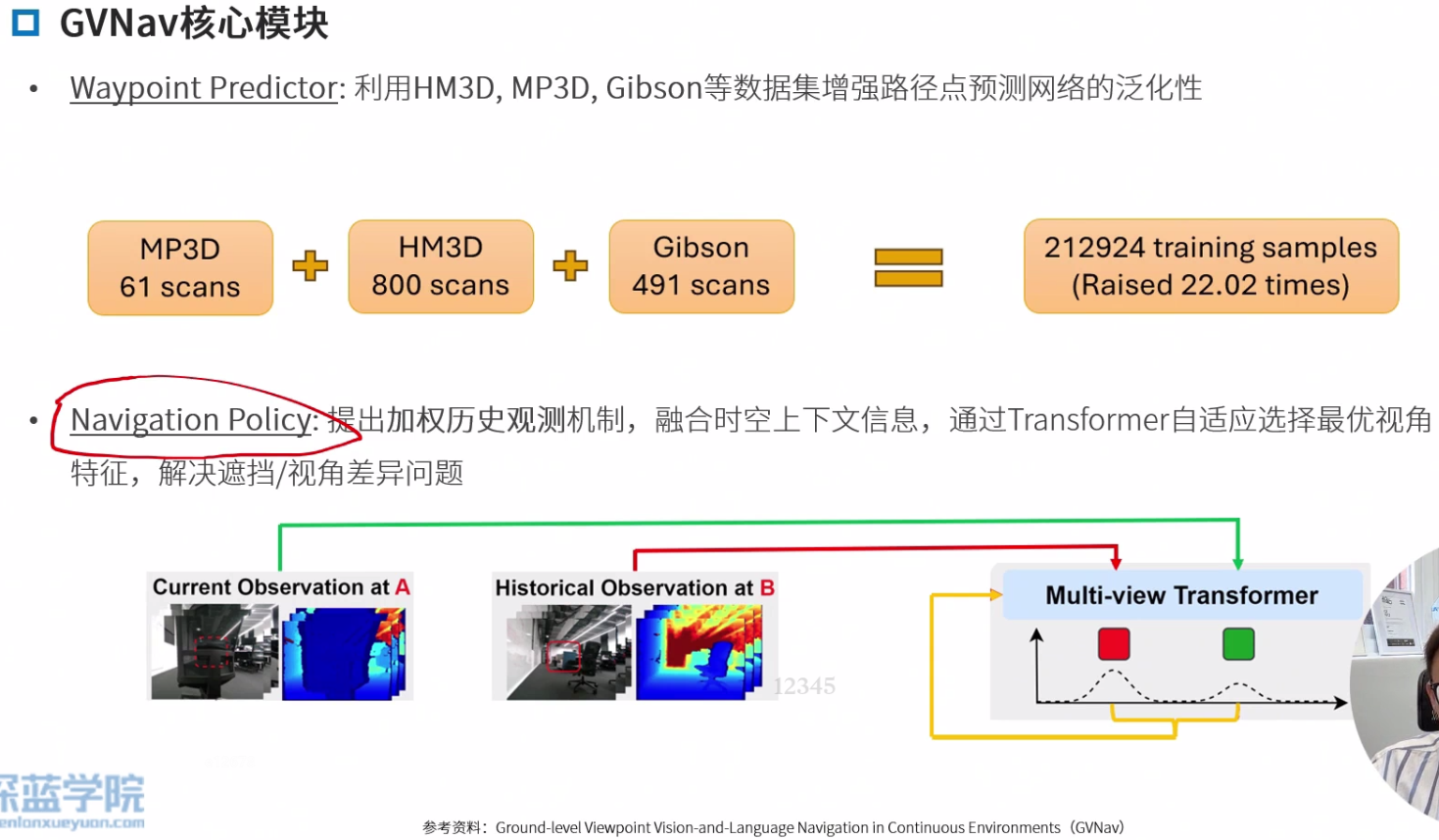
核心模块
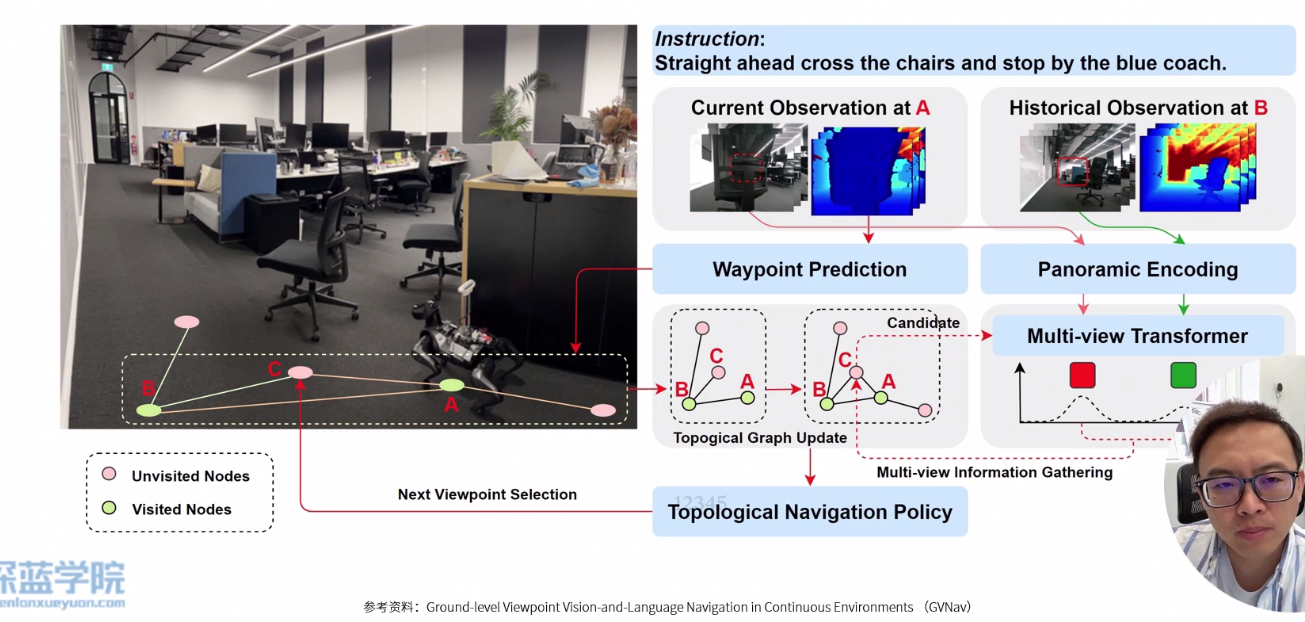
整体框架
局限
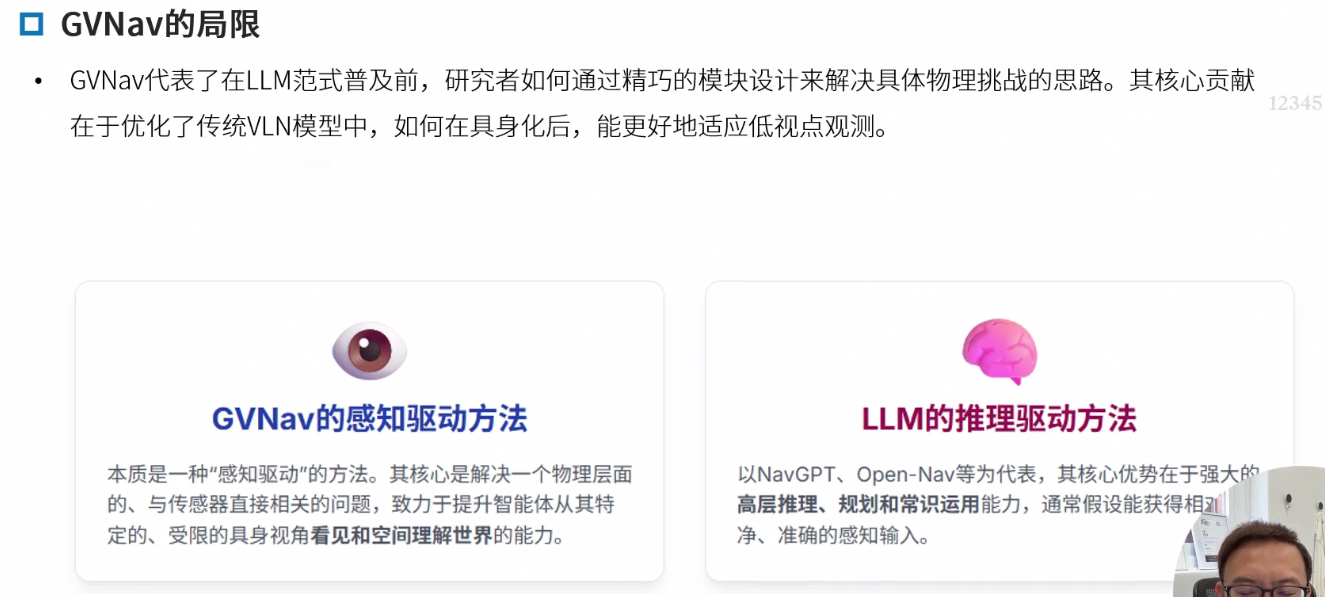
LLM有高层推理、规划和常识运用的能力
SmartWay
以前的缺乏高层推理能力,从错误中纠正的能力
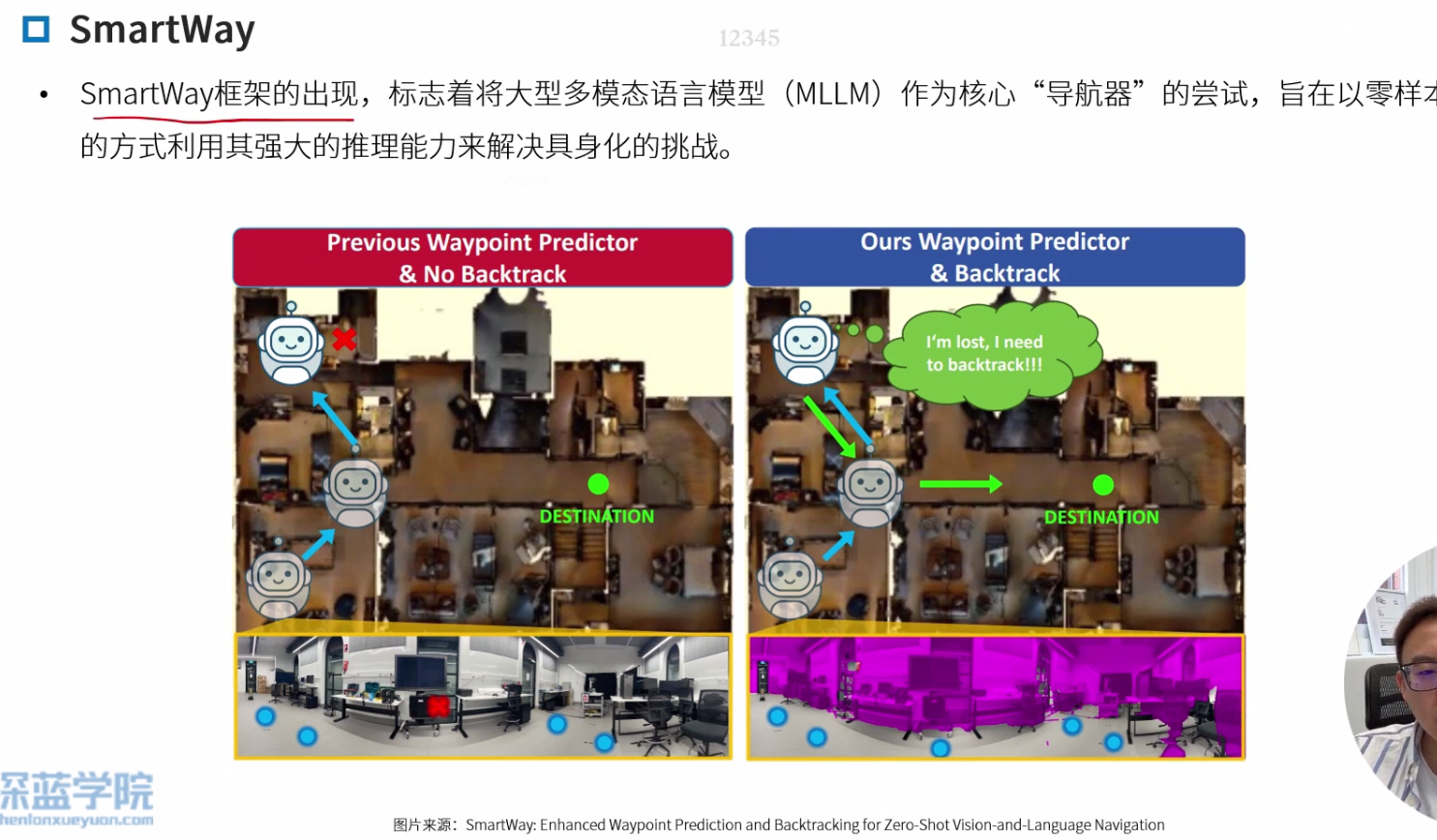
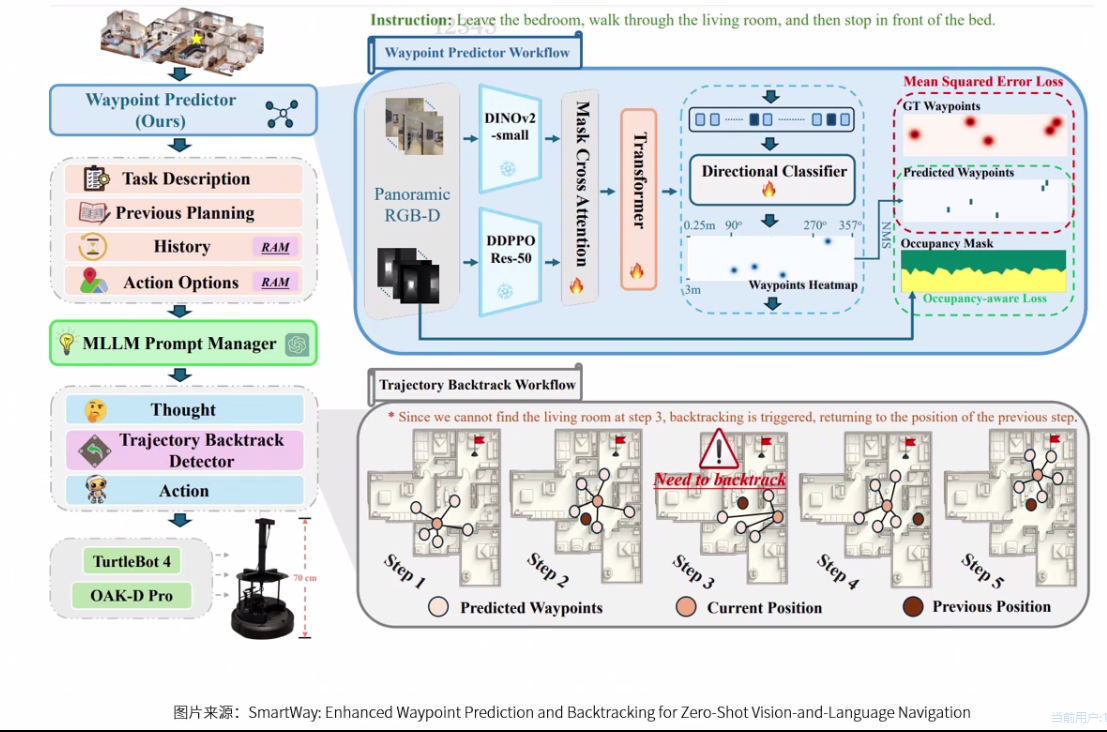
增强路径点预测器
DINOv2

MLLM多模态
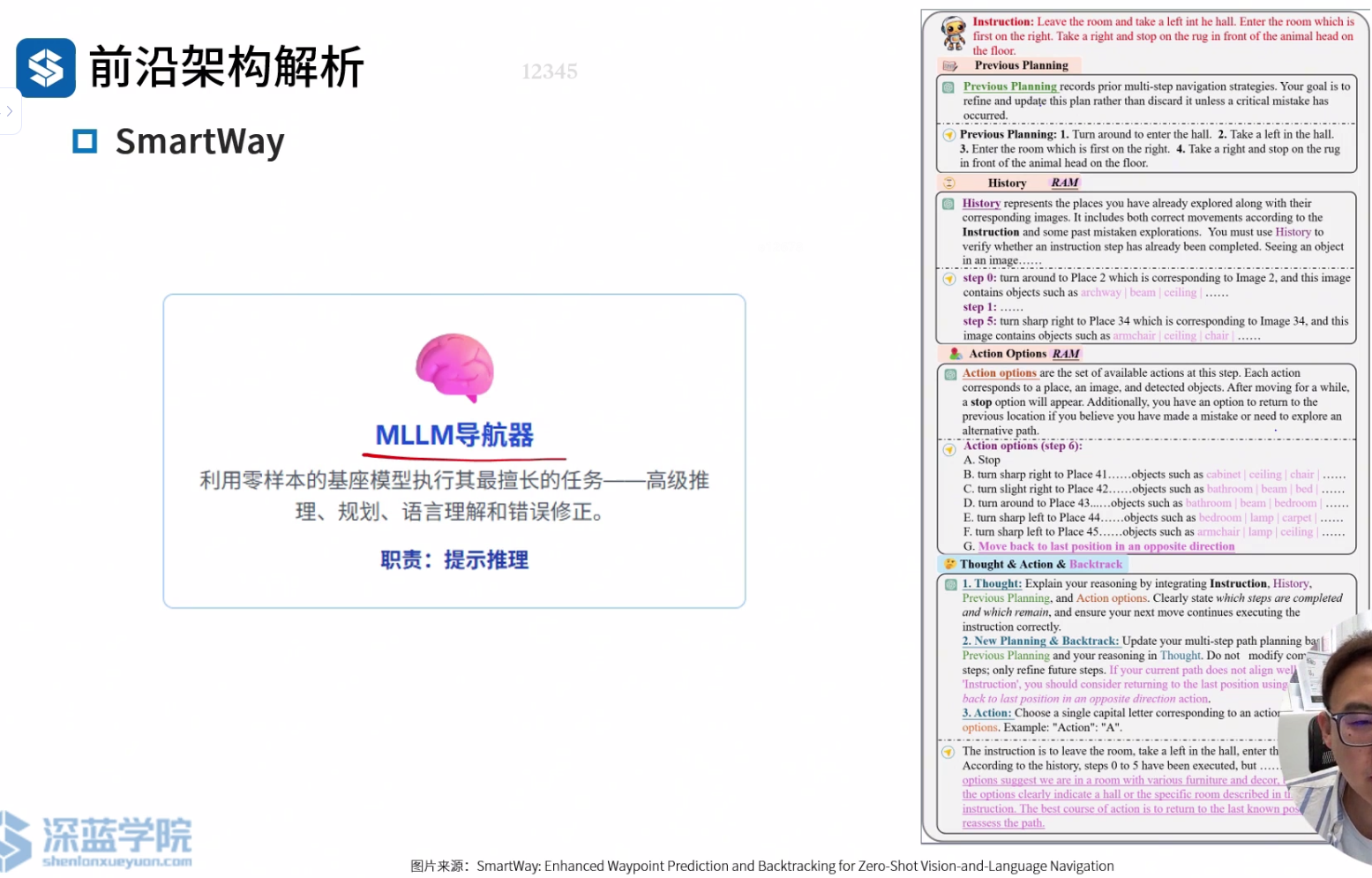

整体框架
局限
 巨大计算开销,推理延迟,推理速度不够快
巨大计算开销,推理延迟,推理速度不够快
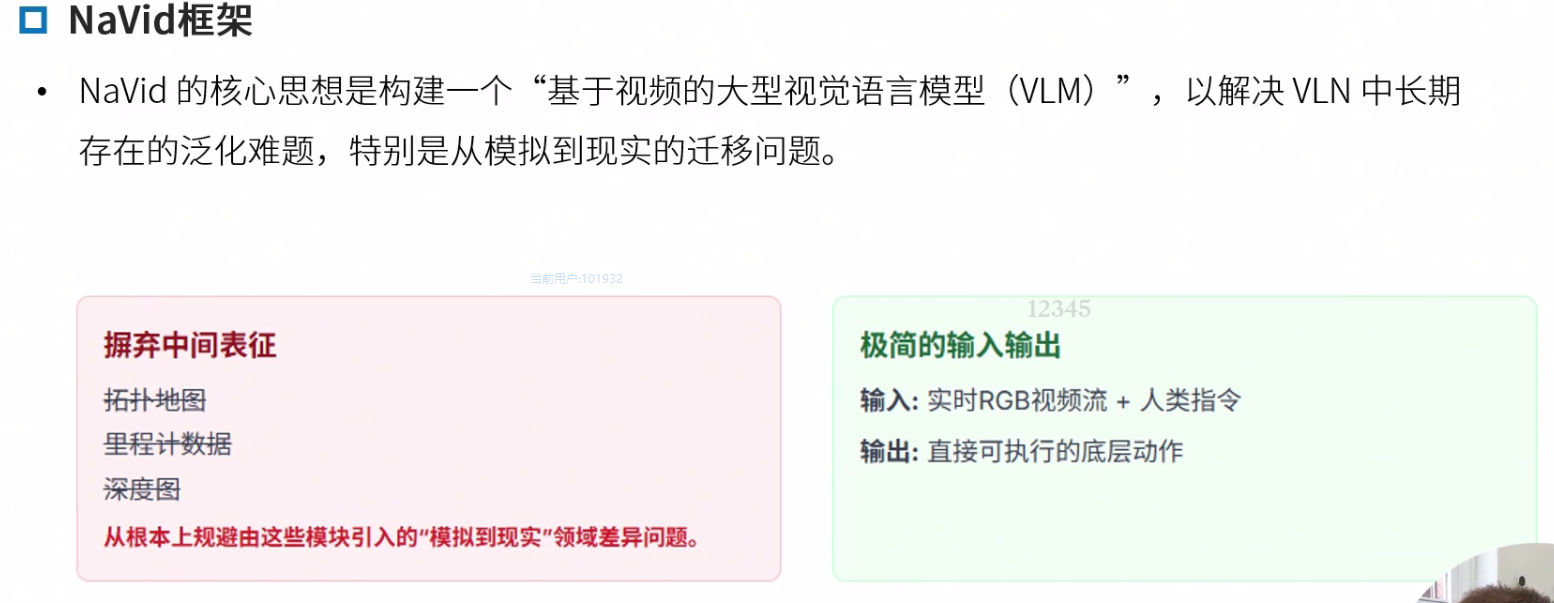
Navid
Navid的核心思想是构建一个“基于视频的大型视觉语言模型(VLM)”,以解决VLN中长期存在的泛化难题,特别是Sim2Real的迁移问题。
是端到到的

Uni-Navid

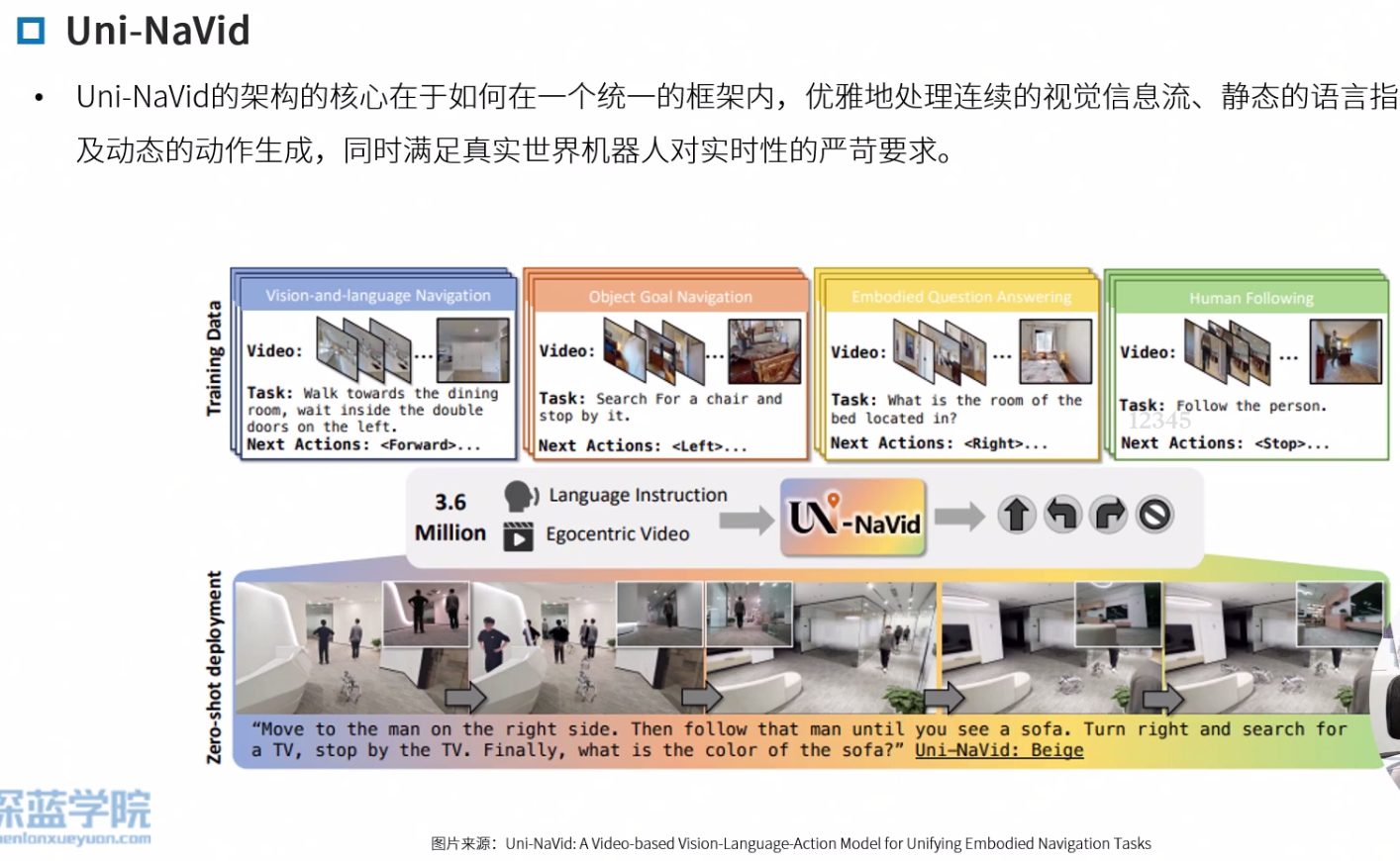
序列到序列的生成任务

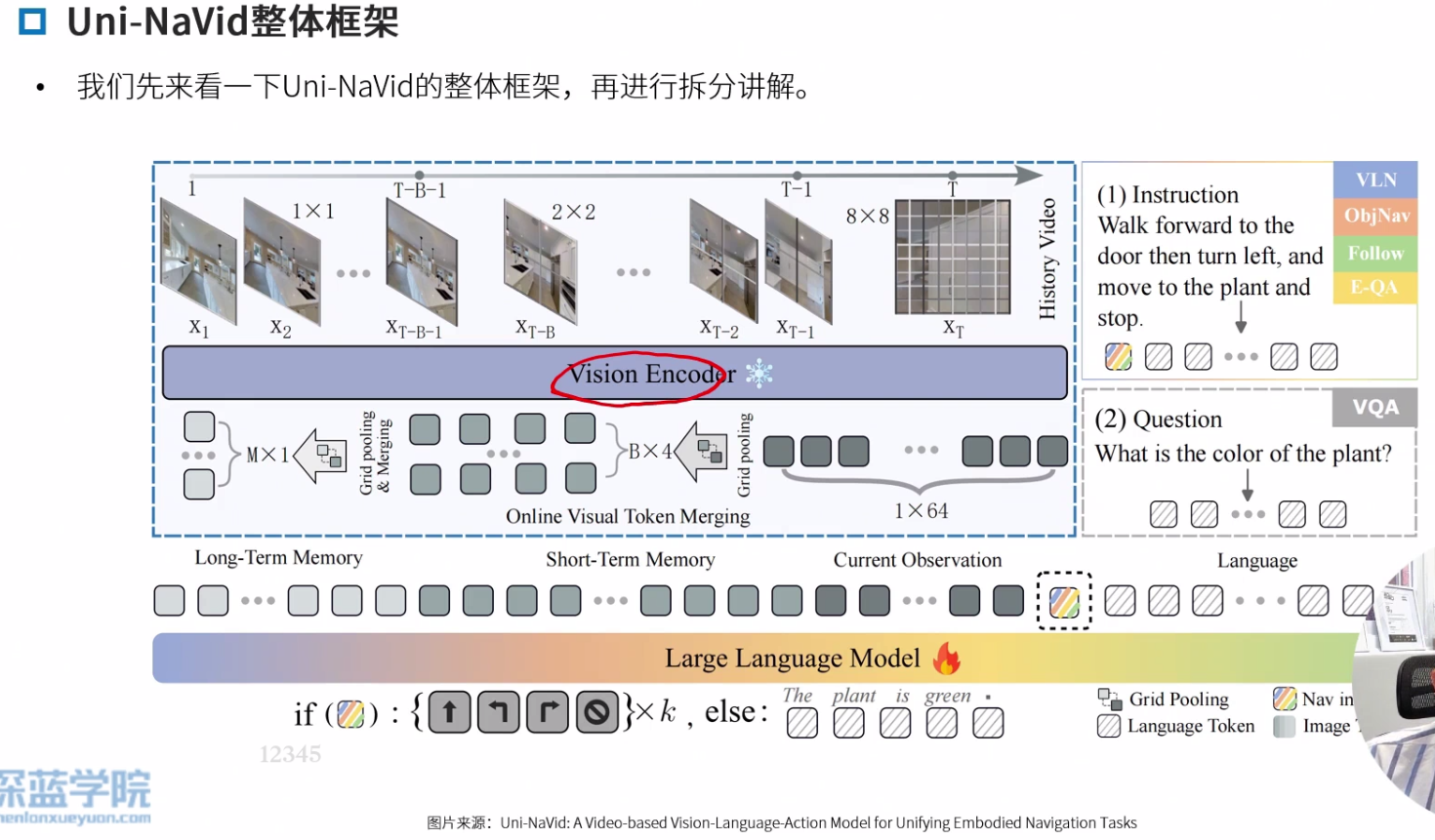
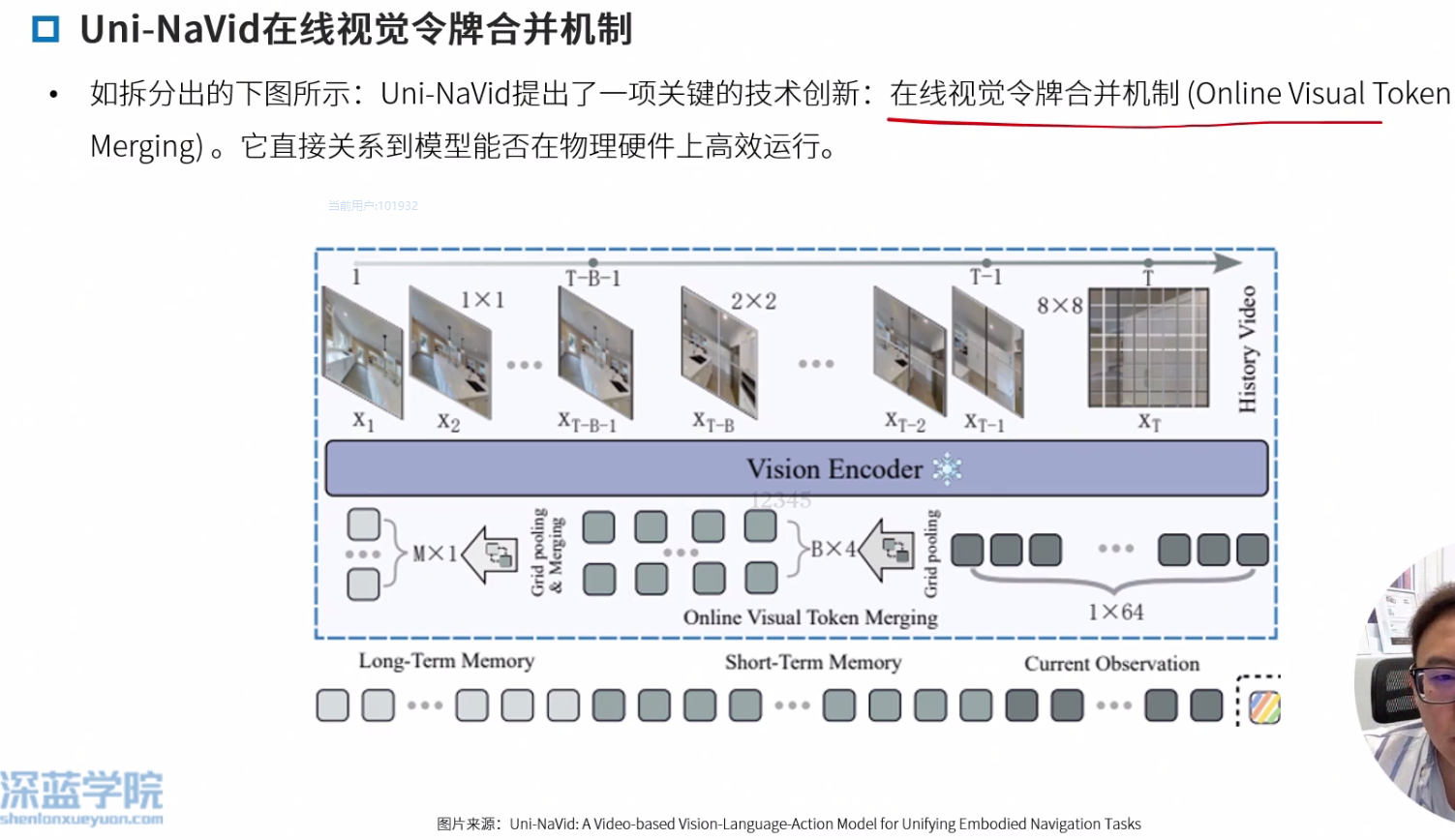
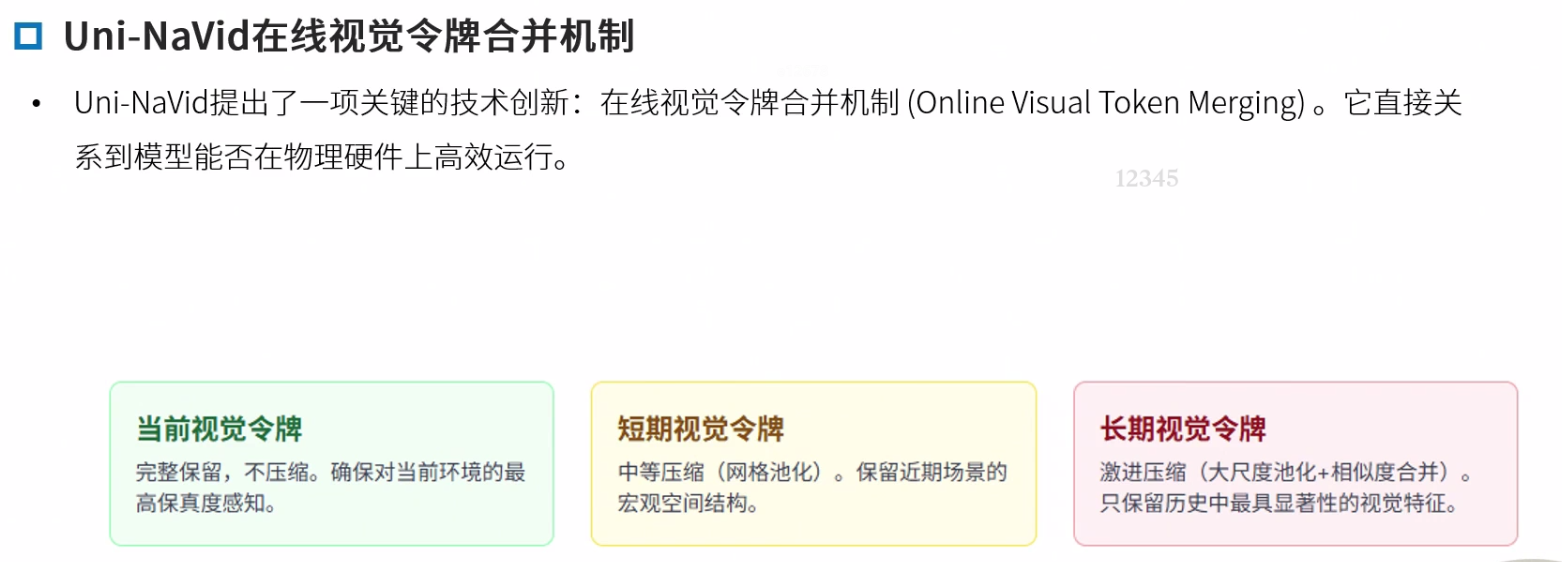
在线视觉令牌合并机制
分层
预见性的动作规划,异步

数据
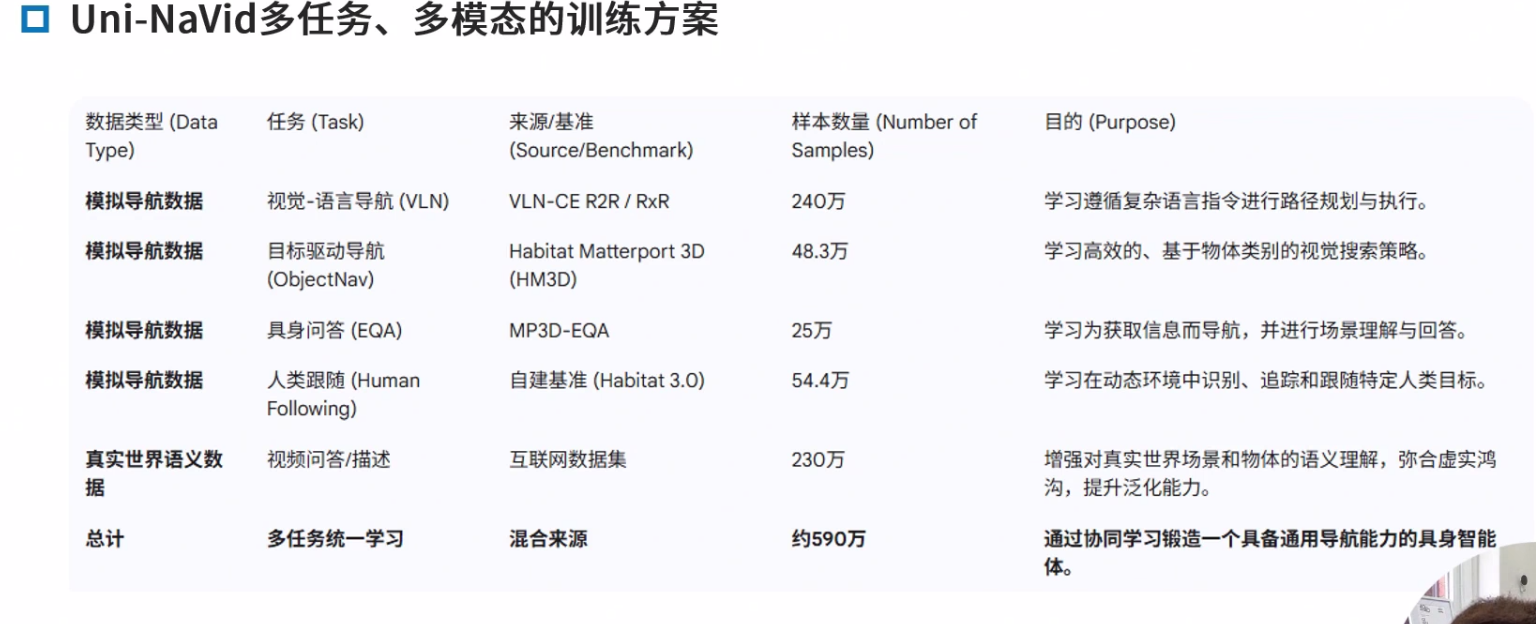
局限和未来

课程总结
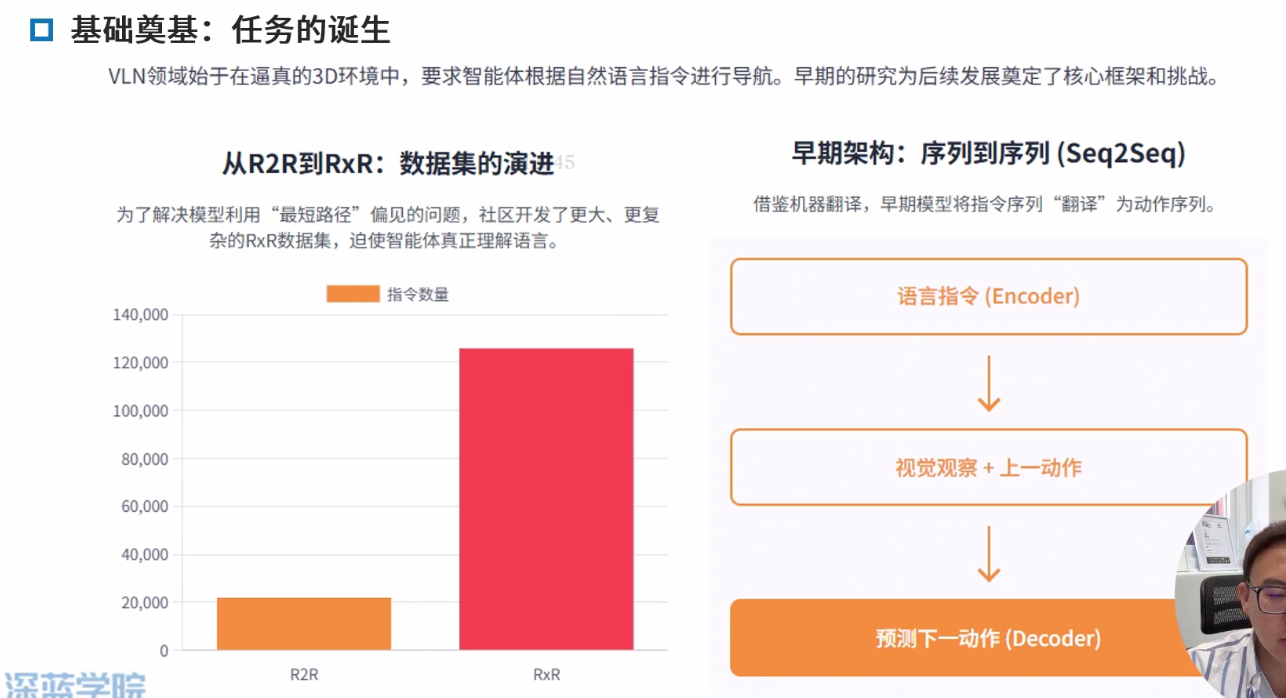
基础奠基:任务的诞生
Learning的角度
泛化能力突破:预训练
大模型时代 LLM
空中VLN

具身化:Sim2Real
